An Open Letter to the Erlang Beginner (or Onlooker)
One of the #erlang regulars, Jesper Louis Andersen (jlouis) recently posted a reply to an old post about whether Erlang is overhyped or not.
I definitely have to agree with jlouis on this one and his blog post is pretty good. His reply stirred a lot of arguments up on social websites such as reddit or Hacker News, but really none of these arguments were new or unknown to the Erlang community. I've decided to write this blog post addressing a few points about it.
The Syntax? Oh God
Erlang's syntax has always caused problems to newcomers (or even some long-time users of the language). Jlouis had great arguments on the syntax with regards to his post: you have to differentiate semantics from syntax itself. Erlang's semantics are what should be seen as important, but it's rarely done.
For what it's worth, I have published another blog post on Erlang's syntax (particularly the punctuation) to maybe make it friendlier overall, but I don't think syntax as a whole is a problem that can be solved for people who don't like it.
I would just add that a different syntax helps getting in a different mindset, which is particularly useful when learning new paradigms. It might seem like something really annoying, but you'd be surprised how often we see people trying to shoehorn whatever concept they know from imperative or OO programming (or even some functional idioms) into Erlang. That just doesn't work most of the time. You have to learn the basics and forcing you out of your comfort zone by way of syntax might help with this. Speaking of which...
Erlang WILL be slow (because you don't know how to use it)
Erlang will be particularly slow when you first use it. Again this is mostly due to not knowing the idioms of functional (or concurrent) languages, how to intuitively work with persistent data structures, when to use different kinds of strings, recursion, storage, etc. This effect won't be as obvious if you know functional programming already.
Then there's the subject of traditional benchmarks (like those in the computer language benchmark game). Traditional benchmarks are usually flawed in one way or another if you try to use them as a way to know how fast your software will be: they focus on a single part of an entire system, stressing one or a few properties at a time. Interesting cases are real-world applications where the difference between IO-bound, Disk-bound and CPU-bound problems aren't compartmentalized in their own boxes, but interact one with each other. What happens when you're disk-bound on a task but queries coming from the network come at a faster rate? What happens when two components wait for the same resource that's slower than both of them? Few benchmarks will demonstrate this very well. In fact, the computer benchmark game explicitly acknowledges this, but unfortunately not all benchmarks do, and not all readers care about such notices. Other benchmarks can be conducted by people who do not understand all the languages or properties of the systems they test (I remember seeing benchmarks where the tester assumed Erlang processes were OS processes that mapped to a processor core directly, which is entirely wrong). Not all benchmarks are useless and Erlang will sometimes be slow for some CPU-bound tasks, but this alone shouldn't discourage you if your problem isn't all about CPU time.
Speed isn't a property of a language, but also a property of your own code and the algorithms chosen (nothing new there). It's also heavily dependent on the architecture of the system that your program will be running on, from the machines chosen to how smartly you cache stuff, organize parts that communicate together, and generally manage to have your code do less. That being said, Erlang doesn't have true arrays or hashmaps with average constant access time; this is going to be a big hurdle to many programmers not used to working without them.
String Handling doesn't matter that often
String handling is one particular thing that Erlang has a bad reputation with. By default, they're linked lists of integers, which isn't particulary memory efficient. Then they're linked lists, so modifying the string is often an O(n) operation. Jlouis described the problem pretty well with his blog post: strings are often overused in many languages — types or objects such as atoms can do the job better.
In Erlang, you can't blindly use a single kind of string and call it a day. You have to think about what the string will be used for: communication between processes, output, storage, etc.? For communication between processes, atoms are particularly efficient. They are to be used as a tag on messages, a label differentiating them from each other. You get constant time comparison and pattern matching (although this is more complex in distributed settings). Then binary strings are particularly space-efficient. They can also break the 'nothing shared' principles of Erlang when large enough (although nobody should build on that property) to gain in space some more. Lastly, you have iolists. An iolist is any list of strings, single characters, binaries, etc. They're loosely defined data structure that allow you to basically shove anything that could be text-related in the same package in any order, and the output drivers (written in C) will handle the flattening and conversion for you. Outputting the message "The sky is blue" could be done as [<<"the">>, 32, [$s,$k,[<<"y ">>,["is"]] | [" ", ["blue"]]], "."]. This is ugly, but this allows constant-time appending and pre-pending without rewriting any existing data, which is something usually not doable with persistent data structures such as lists.
Picking the right data structures will work wonders on letting your code become faster. Sadly, this is not something intuitive and it only comes with experience and some studying of others' code.
It's OO, but pretend it isn't, please
Erlang is sometimes said to be object-oriented in the original meaning of it: each process acts as an object communicating through message passing. While this sounds good, you'll hit a wall if that's how you approach things. Erlang's processes are meant as a way to separate individual components to provide fault-tolerance; not to compose them and have them interacting on a level as low as function calls all the time. Representing a list or a tree node as a process is useless, while they could very well be objects in any OO language.
Erlang's processes are a way to provide fault-tolerance first. This can be tolerance to some weird hardware failure, a programmer error, corrupted data, etc. That an OO-like system emerges from it is purely accidental. Similarly, the kind of gold rush towards parallelism that Erlang had during the last few years (it's what brought me in, too!) is kind of misplaced. Again, parallelism is a byproduct of what Erlang focuses on. You can read more on that in The Hitchhikers Guide to Concurrency.
Lack of types
I realize the usefulness of types. I realize leaving it all up to the compiler helps. I realize it reduces the need for as many tests (although not all of them). The Erlang community realizes it too. So much that Erlang has its own type inference system with annotations that is entirely optional. However, the typing system is kind of funny and is based on success typing. Basically, if types à la Hindley-Milner are overly restrictive in what they allow, success types do the opposite and assume broad types while inferring them, and won't warn you until a condition that will provoke a crash (or breaches one of your annotations) is 100% sure to have been found. It's worth reading about them in Practical Type Inference Based on Success Typings.
Now, having something enforcing strict typing before compiling or running the code is pretty nice, but the point I want to make here is that it's not the end of all programming woes. Errors will happen anyway in most projects. What do you do when they happen in running code? If your language of choice has no solution for that, you might be interested in learning more about how Erlang does things. More on this later.
And ugh, the documentation is terrible!
It is and it is not. Erlang's manuals are mostly written as a reference for people who know them already. It's often hard to pick up something new just by reading doc; purpose isn't frequently explained, the raison d'être of a library is not always there, and precise examples on how to use them are sparse. Again, they are a reference, not a tutorial. As a reference, they do a great job—except the part where you need to navigate through them.
Before providing explanations, I'll link to erldocs.com, an alternative documentation site written by Dale Harvey. It's searchable and does a great job at helping you find out specific functions you need. There's also demo.erlang.org if you want an alternative alternative.
If you feel like staying with the official site, I'll show you how to navigate it, because again it's made for people who know Erlang and it's hard to get around it.
In Erlang, every standalone bit of code you might release can be stored as an application. Erlang applications aren't like your normal applications. They can hold pieces of code that need to be stopped and started (like a web server) from the Erlang shell itself, or just a flat group of modules that can be used as a library. So the standard library containing modules for lists, dictionaries, trees, sets, etc. exits under the 'stdlib' application. You can get an index of all applications on this page.
Now if you click some applications there, say kernel, under basic, you will see a list of all modules in kernel. This application has only a reference manual -- no tutorial so to say. If you instead look for the debugger, you'll see a link towards the debugger users' guide. This one should contain friendlier documentation. Again, not all Erlang applications contain nice tutorials like the debugger does, but it's a good way to get started. Once you know your way around it, you might end up thinking the Erlang documentation is pretty damn good. If you don't, you can still pay us a little visit in #erlang on freenode (you need a registered nickname there).
Focus on maintenance
We can now start thinking positive a little bit. Erlang was (and still is) developed somewhat iteratively with lots of feedback from engineers in the industry. Back in the day, it was telecom guys 'building bridges' and needing real reliability. Nowadays, these guys are still there, but a whole lot of people from other domains are added to the group. Overall, this gave Erlang the perspective of focusing on maintenance and making things work in the long run.
Most tools and libraries developed for Erlang are built with the idea that they will be running for years uninterrupted. Erlang's code is coming with a comprehensive test suite, a commitment to backwards compatibility (this happens to slow language development down quite a bit sometimes), and the whole system is meant to be fiddled with and debuggable.
Erlang supports tracing on a VM level: you can set it on a per-process basis, see what happens with messages sent and received, function calls. These tracing flags can be made so the tracing only fires for functions from a given module or functions with specific arguments. You can also choose how processes will inherit the processing flags, where the traces are sent (as messages) to be handled, etc. This tracing allows a wide set of tools to be built: a bunch of profilers, debuggers, code analysers, etc. They can all be started and stopped when you want, even on production code, without a problem.
Erlang also has helpful applications such as a system-wide logger (which can be extended and configured transparently), log viewer, process managers and viewers, tools to see the process hierarchies currently running, tools to monitor the memory used, ways to start remote nodes programmatically, a structure to update entire systems without stopping them from running, its own database, snmp integration tools, testing frameworks and so on.
Then add the OTP behaviours. They are modules that define a generic and well-behaved implementation of some known model (which most of us would get wrong at first, frankly), which you fill in with your application-specific details. The standard ones include generic client-server models, finite state machines, event handlers, supervisor processes, generic application structures, etc. Getting into the Erlang land means you'll often have to write your own solutions to your problems, but the whole framework and toolset around it is provided to you and it can be a real pleasure to work with in the end.
There is also the question of interoperability: what happens when you want to interact with other languages and applications? After all, Erlang is mainly a server language and you don't really get to choose what other software on the server is written in. Erlang has many ways to interface with C code or other languages (or already built software): ports, port drivers (also linked-in drivers), C nodes and Natively Implemented Functions (NIFs). Then you can add protocols such as erl_interface or BERT if you need more options
All these tracing tools, maintenance tools and generic behaviours are there because the people in charge of Erlang/OTP understand what real-world programming requires. They understand that no matter what precautions you take, errors will happen and systems will need to cope with it. This brings me back to my earlier point about dealing with failure on top of preventing it.
Error Handling
This is the core of it all. When you first hear about Erlang, you hear about concurrency, actors, functional languages, scaling, etc. That's what sells. You also hear about fault-tolerance. If you're like me, it frankly won't mean much to you at first. It takes a while before you explore all the fault-tolerance constructs of Erlang and you begin appreciating them. It's not love at first sight, but an acquired taste.
Everything in Erlang was built for fault-tolerance, including concurrency and distribution. You can read The Hitchhikers Guide to Concurrency for short details on that. Concurrency and distribution can handle 'failure in the large' for you, and additional tools such as failover and takeover applications help with this. You can also access remote nodes, redirect output, force local and/or remote nodes to reload code without ever stopping its execution, etc. But what about failure on a more granular level?
You might have heard of supervision trees. Basically, Erlang processes can monitor other processes to know if and why they went down or if they terminated successfully. They can also be linked to each other in a way that says "Hey, I depend on that other process. If it goes down, I want to go down too!", which helps limit how far errors can creep into your system before they take over everything. This is done by stopping whatever this part of the application was doing and restarting from a known state. The restarting is handled by a supervisor. This practice is generally known as let it crash. This is a bit weird at first, but what this really means is only fix the errors you know how to fix — the Erlang runtime is made to handle the other kinds of errors without a problem (and they can even be logged for you automatically).
The other [and most amazing, IMO] aspect of using concurrent actors to do error management is that it shifts the perspective of where exceptions are to be handled. In most languages, exceptions are managed from within the execution flow of the program (on the left on the diagram below). The problem with this is that your regular code needs to handle outstanding errors on every level or you just delegate the burden of making things safe to the layer above until you end up having the eternal top-level try ... catch. It's more complex than that in the real world, but that's generally what it looks like. Erlang supports this model too. However, it also supports supervision trees, which change your program structure in the way shown on the right:
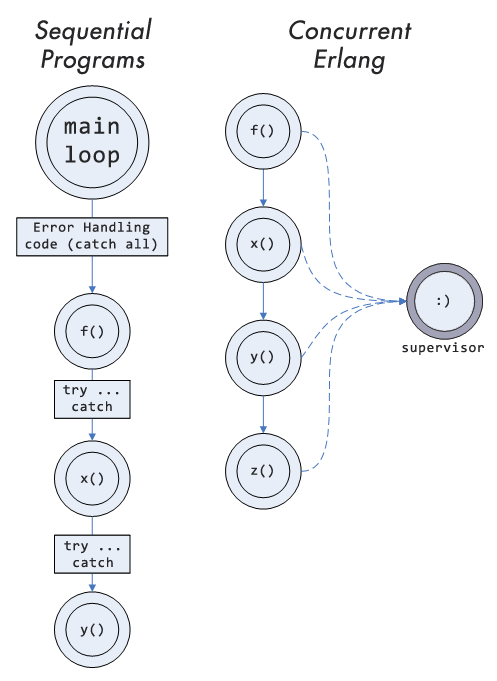
What I meant with this diagram is that worker processes run code normally, and errors are handled by the aforementioned supervisor processes. This means that the burden of error handling is shifted from being tangled with your standard and correct execution path to a model where it is handled literally in parallel to it. This lets you organize your code in a non-defensive manner while helping keeping it more stable at the same time. Your correct code is more concise, easier to follow and thus easier to maintain and simpler to reason about.
This is not to say standard exceptions are not an acceptable way to do things. They're still pretty useful. However, there is more than one class of error that can happen in software, and I think Erlang deals with this beautifully, in a manner unseen by most languages out there. In my opinion, this concept of supervision trees is what Erlang really is about.
Hot Code Reloading
This text wouldn't be complete without mentioning this. Server-side software usually needs to run forever, without interruption. Web developers are used to languages like PHP, Python, Javascript (with node.js) and Ruby being able to handle large deployments without a problem by updating servers one by one, until they're all running the new version of the code. In many cases, this is a good and safe way to handle things: queries come and go, are replied to quickly and the next one will run on the updated version of the software. Hooray.
There's one little problem with this, though. What do you do when the user's query can basically last days or weeks? Let's imagine an IRC bouncer/gateway as an example. If you want to change some vital code, you'll need to take a few servers down. User sessions can either be migrated (which is painful and will require some very special code to handle) or just killed. Whatever you choose, it's either going to be painful for you or the user.
Hot code reloading done the Erlang way allows you to bypass that. You can update code without ever stopping it or losing state. It just knows that a new version of some module was loaded and switches to it automatically, without interrupting the service. In fact, this is one of the reasons why the guys from IRCCloud used Erlang: they can upgrade entire clusters without ever disconnecting anyone.
And so to actually finish this damn thing
I love Erlang. There are many places where it is not what you need. Mostly anything where the CPU is the biggest bottleneck is something I'd think twice about before using Erlang. For other stuff, I'd give it a try. The thing is, Erlang the language is alright. There are inconsistencies here and there, records' syntax sucks (and the whole syntax as a whole according to some), working with the AST is a dirty job, etc. But it does the job and has very well defined semantics.
When I'm programming Erlang, I sometimes miss the speed of some operations, the possibility to have real arrays. I miss native hashes. I miss wide adoption and larger community support (although Erlang's community is fantastic). I miss the ability to go open up any algorithm book and not have to mentally rewrite it to work with recursion, single assignment and persistent data structures.
However, Erlang the environment is excellent. Whenever I work in another dynamic language, I miss Dialyzer. Whenever I work in any other language, I miss supervision trees. I miss the great modularity of lightweight processes. I miss the ability to easily have event-driven code, where each actor acts like a tiny daemon waiting to be called to action. I miss the concept of really distributed responsibility. I miss the excellent OTP framework. I miss pattern matching.
It's not all great, not all bad. I do hope more languages will borrow concepts from Erlang. It's not the end all be all, but it's a damn good step and it's worth giving it a serious try.