Code Janitor: nobody's dream, everyone's job (and how Erlang can help)
Maintenance Sucks
My first programming job was being a web developer on a decade-old dating site that still went strong. It was bad on many points: dead code, things nobody knew how they worked or if they even worked at all, no idea why things were built the way they were, and so on.

The whole job was mostly maintenance, and developers on the team were all anxious in hopes they might get to work on a new bit of the system or be allowed to rewrite a component soon. The prospect of being able to play with new code, not having to do the programming equivalent of walking through a forest of cobwebs, was great. Maintaining old code was the mandatory work to receive your writing-new-code pittance, the necessary evil in the programming universe. Entropy is such that you would sink energy untangling the massive old code base until it was a little bit better and you were much worse off.
I'm pretty sure I'm not alone to have lived this experience. It's long hours of trying to figure out what the old code is doing, mostly, and then fixing things with hopes of not breaking some undocumented behaviour someone was relying on, possibly in a completely unrelated part of the system. And most of the time you're not even fixing things, you're just keeping them up to date with changing rules. You're adding to the number of things that may fail, rather than improving it.
In the state of the art in the world of software, it is believed that about 70 percent of developer time is spent doing software maintenance, leaving 30 percent for development [1]. Other sources would confirm these figures by mentioning that software maintenance takes between 60% and 80% of the product's total lifecycle costs [2]. Where does all that time go? While one can suggest that a lot of time is sunk browsing stuff online or chatting on IRC, the time is usually split between 4 major categories, as defined by IEEE:
- Corrective, where the objective is to fix bugs;
- Adaptive, where you change the software to keep it going with an evolving environment;
- Perfective, where you try to make the software better for the customer (at their demand), or easier to maintain;
- Emergencies, where you do stuff real quick just to keep the system working due to unexpected circumstances.
It turns out that Adaptive and Perfective maintenance take the vast majority of maintenance time, between 75% to 80% of the time in total [3]. Bug fixing just won't consume that much time, generally speaking. Of all the effort made to write good programs, most of our time will be spent trying to improve it (likely due to change in requirements), not fixing it because it was full of errors.
As the program is being used, its users become dissatisfied with it due to how they adapt to it and they can see new needs arise. Either that, or the world the program evolves in changes in ways that make it obsolete. This has been specified as Lehman's First Law [4]:
A program that is used and that as an implementation of its specification reflects some other reality, undergoes continual change or becomes progressively less useful. The change or decay process continues until it is judged more cost effective to replace the system with a recreated version.
The idea is that all programs need to change from time to time, or at least, all those that do not come from a formal specification that live in a rather immutable environment. Things may become a problem when you consider Lehman's second law:
As an evolving program is continually changed, its complexity, reflecting deteriorating structure, increases unless work is done to maintain or reduce it.
Basically, as time goes, programs require change, and the more change they require, the harder they become to change. If you don't take action to make sure maintenance is easier with time, cruft tends to accumulate until it can't be dealt with anymore and it becomes more interesting to start from scratch.
The insidious thing is that the computer doesn't worry about complexity — it just executes what you tell it to. People have a problem with complexity. When there is more complexity, understanding something takes more time. That's where it hurts. In fact, 22.5% to 57.6% of the time spent in any software project is spent trying to understand the system, maintenance and development included.
Without making an explicit effort to reduce the complexity of a system, and without thinking of making your software maintainable from the beginning, you end up with this:

Instead of this:

It's obvious that making changes to the set-up in the second pictures will take less time than modifying the first picture's set-up. Nobody will claim the opposite. Given such a perspective, it's easy to see the long-term advantages of making a conscious effort to keep things maintainable. Yet, most businesses do not care about it much:
Beath and Swanson report that 25% of the people doing maintenance are students and up to 61% are new hires. Pigoski confirms that 60% to 80% of the maintenance staff is newly hired personnel. Maintenance is still perceived by many organizations as a non strategic issue, and this explain why it is staffed with students and new hired people. To compound the problem there is the fact that most Universities do not teach software maintenance, and maintenance is very rarely taught in corporate training and education programs.
That hurts. And that's in good part why maintenance sucks. It takes a lot of time, nobody cares about it nearly enough while it's the biggest time drain in a project. Maintenance is left as an afterthought, and most of the time in maintaining software is spent trying to figuring out what the hell goes on from whatever source is available.
I said what what, in the code
Maintenance sucks, it's a major part of development, and most of it is really all about trying to figure out what the hell the system is doing. The solution seems simple, right? Just document stuff!
Now if we were sitting in a large room and I were to ask people for a show of hands on whether they trust the documentation of the system they're working on, I doubt I'd get a majority of hands up in the air. Generally speaking, people tend to mention documentation low on the list of information sources they feel is important, most likely because it's generally outdated or just not there [7].
When it comes to gathering information and trying to understand how stuff works, programmers will tend to trust sources in the following order [8]:
- Code. 7 in 10 industrial development groups looked to the code as their primary source of information, more often when the developer is already knowledgeable about the code base.
- Coworkers. Usually this is about skipping code deciphering by asking someone who has done it before to help you. Reusing acquired knowledge rather than rediscovering things.
- Tools that keep a knowledgebase, such as bug trackers.
- Documentation of any kind.
That's a huge portion of people going to code first. Code is king. Long live the code.
Enter Reverse Engineering and Re-Engineering
Once you get to the step where code is your best source of information, you get to reverse engineer the system you must maintain: you observe it, identify its components, identify its dependencies, figure out how everything meshes (or tangles) together. You deconstruct it mentally. Once you figured out what the system does and what it should do, you mentally reassemble it to make it work the way you want. You take that abstract concept you've got of how things should be, and make it happen by re-engineering the system.
As a programmer, getting maintenance right requires you to have a good understanding of the source you're going to change. Everything you don't understand has the potential to become a wart in the code, making the next round of maintenance harder. Re-engineering should leave things as clean (or cleaner) than they were when you first got them. When this doesn't happen, someone will have to clean the mess later, otherwise the project will eventually become unmaintainable and will need to be rewritten from scratch.
How To Get It Done, in Erlang
There are hundreds of ways to do things right (or wrong) in hundreds of languages. I'm going to put full focus on Erlang, because that's what the title of the blog post says and it would be mean to lie this late in the text. The principles discussed are valid everywhere, but their application is language-specific.
When I asked 169 Erlang programmers (most of them describing themselves as professionals) what they thought was important for maintenance [9], they answered as follows:
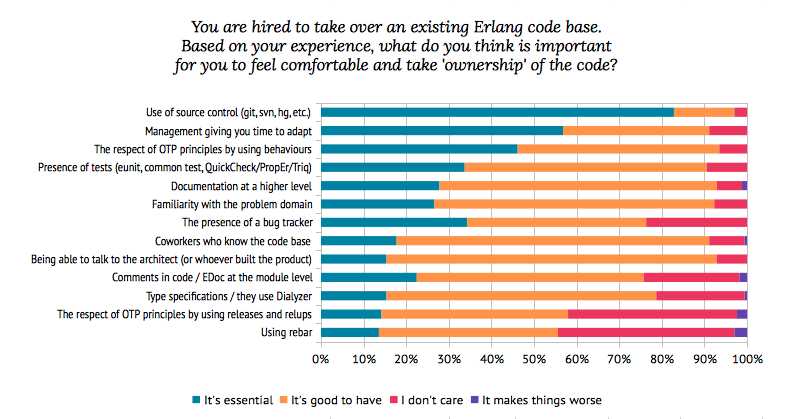
Out of the 10 first categories by importance, 9 of them are not technically specific to Erlang or OTP (tests are a grey area as the question mentioned specific frameworks). This graph alone is a good way to know what to prioritize.
Source control is somewhat of a no-brainer, with tools getting much better in the last few years. Source control lets you know who wrote what, when it happened, can let you search for bugs, and lets you manage the complexity of concurrent changes to a code base. Time to adapt is also simple to understand when we think back on how much time is necessary to understand code bases in maintenance, across all languages.
Tests give you confidence in the code base, tell you how to use the code, can act as documentation, and should let you be confident the new toaster you assembled with not burn your house down and toast your family to a crisp. There is likely an expected quality to tests — nobody likes bad tests. I won't get into testing methodologies as there's a crapload of them and many ways to do things, but if you're building an Erlang product, investing in learning how to test your code is rather essential in the long run.
In any case, only the use of OTP behaviours is Erlang-specific in the top 9, but it's a very important one. In fact, it's the one I want to spend more time on. How come OTP behaviours get to be so important, taking precedence over so many standard things such as tests, coworkers, documentation, comments, and so on? Well the first easy explanation is that OTP behaviours are code, and people trust code. Thus it's going to be important. But that's obviously not all there is to it, because things like type specifications or comments in code rank way lower and still have to do with code.
Why OTP Matters
If you know OTP, there's this feeling that any application that respects OTP is somewhat easy to get into. OTP components tend to be self-contained, with cleanly defined interfaces. You can think of them as black boxes quite easily.
These components are called behaviours, and they come in a few flavours. You have workers, which may act like message hubs, resource owners, or independent agents in a system. You also have supervisors. Supervisors force workers to fit a neatly organized structure. They force you to think of all the relationships between the subcomponents of a system: how they should be started, how they should be taken down, how they should crash, and how closely they are related with one another.
Then one level above, you have OTP applications. They're a higher level behaviour that forces you to organize all your related supervisors in a tree with a single supervisor at the top. Where supervisors will force you to think of how workers fit together, an OTP application will force you to think of how clusters of workers (under supervisors) will need to be organized. They will help highlight how parts of a system interact together, and make the code be very explicit about it.
Each application can state what other applications it depends on, like blocks in a sub-system, and they can all be started or loaded with different priorities (those that are vital to the application, those that are not, and so on), that will tell you how hard the system should crash when it needs to.
In a nutshell, OTP thus forces a common development pattern on every single programmer, where all components are to be properly isolated from each other through clean interfaces, with dependencies and start orders cleanly defined. Each of these components has its own building blocks cleanly sorted in a hierarchy based on supervision trees, where related workers are put together or away from each other.
1. Turning Jenga into Lego
Maintenance often sounds like playing a game of Jenga. You first build a decent tower on the first version of the software, and as long as you change things at the top of the tower, nobody has anything to complain about. The deeper in the system you go, the harder changes are to make. Everything you built likely had assumptions on how things ought to be done to be optimal at their core. Whenever a change in requirements asks you to reconsider these concepts, it's like removing one of the lowest Jenga blocks, and replacing it by a different one. Either you'll restrict yourself as much as possible to make everything fit under the current format, or you'll be forced to change a bunch of things all around to absorb the changes. Until, inevitably...

General good practices will help: well-defined interfaces, not sharing implementation details or making assumption about them, tests to make sure you don't break anything, be careful of your choice of data structure, and so on.
Erlang itself will do something rather neat for this. Because OTP application are in different processes and processes share nothing in order to keep distributed semantics at a local level, you have to establish protocols between components. The whole programming model behind Erlang assumes failures, and OTP embraces it. Erlang assumes you're going to build a Jenga tower and that it will fall down at some point. Everything down from isolated processes and message passing up to OTP applications is there to support this. This makes changes to applications somewhat easier to do than average.
To illustrate my point, let's take a look at a quick dependency graph I generated (with a script written in 15 minutes) about Riak:
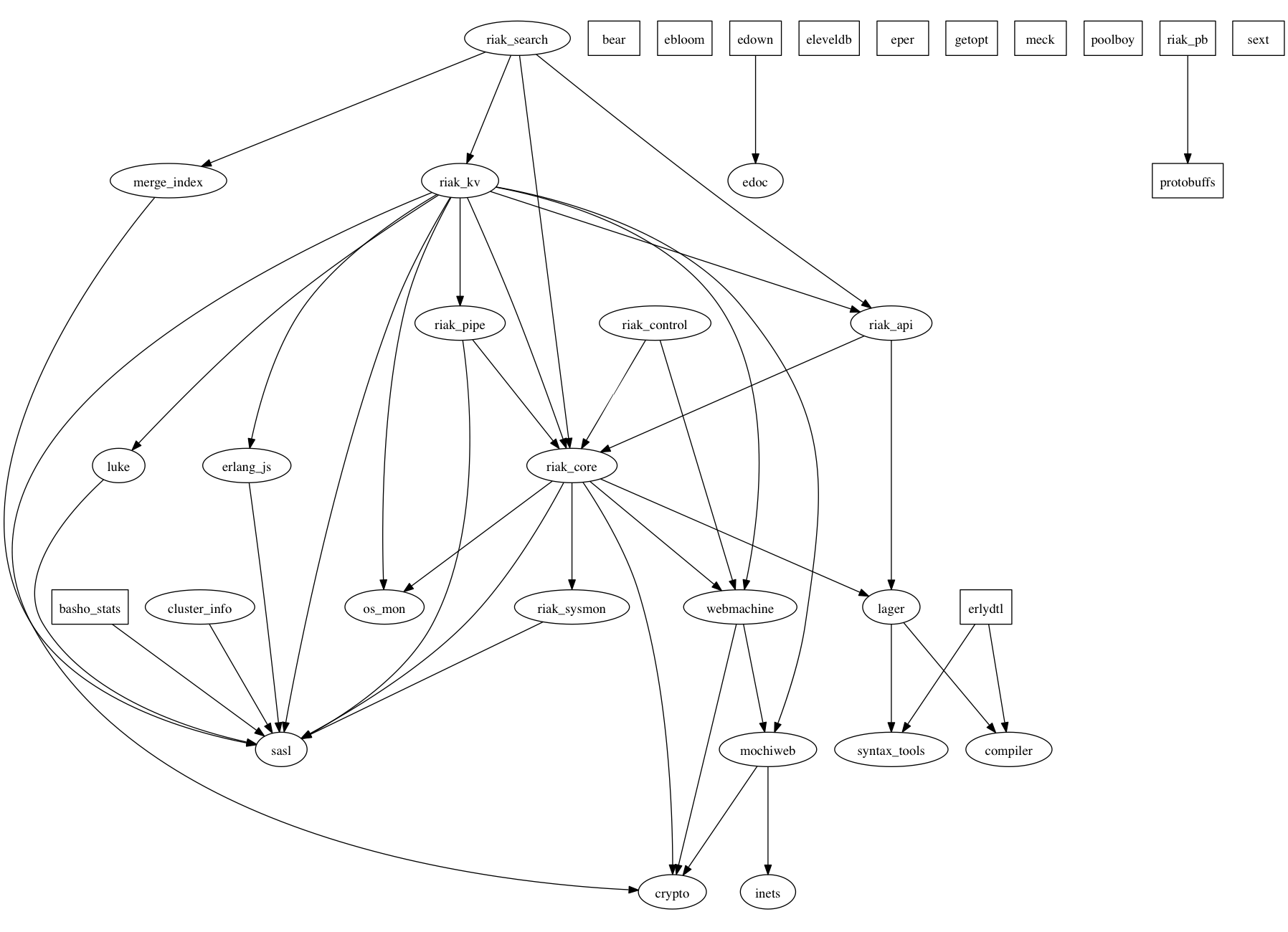
The regular process-based applications are represented as circular nodes, while library applications (not process-based) are represented as rectangles. I've also removed kernel and stdlib from the graph given all applications depend on them. Even though we can see that the Basho guys appear to not care that much about setting the dependencies they have on library applications, this kind of hierarchy has its use.
When respecting OTP standards, such graphs make it instantly obvious what app depends on what other app, and given very little is shared between applications, it is rather simple to figure out what the impacts of modifying an application will be on the whole system without even needing to go down to the module level. If I'm planning to change the behaviour of riak_sysmon, I only need to ask the guys from riak_core how they use it to have an idea of what it impacts, and look at what depends on riak_core to see how tricky upgrading it would be. If I don't change the message-based protocol, I can do whatever I want with the innards of the app.
Such isolation also means that if I'm writing crap code, or picking a terribly bad way to represent my data, the impact will be limited throughout the system. I will be able to change the bad parts while limiting the impact I'm having on the good parts.
In fact, it's possible to restart only one or more applications if they have important changes that makes it hard to upgrade them without stopping, at run time. Basically, while Erlang often makes it possible to just load new code in the VM and upgrade the system as it runs, it's sometimes desirable to start from a fresh state. OTP applications allow you to restart isolated components of the system independently, allowing you to get the clean state you need, without dropping the state you can't afford to lose in other components.
This is usually the kind of stuff you'll see done when your non-Erlang system makes extensive use of web services or more generally, distribution. When you build systems that have to keep that kind of architecture in mind, you change how you program a bit. You become aware of high latency, possible failures, netsplits. You bake in these possibilities in your design. You program expecting things you don't control to go bad. These assumptions are already at the core foundations of Erlang and OTP, and they are available without going distributed or using web services. It's what makes it possible to see your software stack as a Lego tower rather than a Jenga tower.
2. Understanding a System from Afar
The structure OTP imposes on developers is not domain-specific. People developing web applications will use it the same way people developing 3D modelers, people writing scripts to automate tasks, writing database engines, or people using it for routing or middleware will use it. It is low-level enough to be general, but high-level enough to make development easier without large domain-specific frameworks on top of it.
This means that no matter what Erlang code base you end up maintaining, you can figure out how things are laid out and organized very quickly. Take the Riak structure above, for example. Yes, it's useful to figure out what the dependencies between applications are, but it's also useful to explore and understand code. If you get a code base that you don't know at all, the application hierarchies gives you a quick map of the system, starting at the top with the high level logic and code, and then successively going at lower and lower levels.
Each OTP application has its own application file that will contain a description of what the application should do, specify its dependencies, the modules it contains, its common configuration variables, and the module to start the top-level supervisor. Following this supervisor will reveal the hierarchy mentioned earlier.
Given this structure, it's rather simple to rapidly gain a general, abstracted idea of how an Erlang system is built. For more experienced Erlang developers reading this, this means you should explicitly care about your app files, and not just let rebar handle it all for you the way it handles modules, because it won't (and it isn't supposed to).
3. Names to well-known, standardized patterns
Of course, it's not enough to look at OTP apps and call it a day. Once you've got the App's structure figured out and that you have an idea of what your changes will break, you have to go down in the code.
In many languages, you will get an idea of what code does via comments (Python docstrings, javadoc, block or inline comments), type signatures (I'm looking at you, Haskellers), Names (class, method, module, and/or function names) or design patterns (A wild FactoryFactory has appeared!). While Erlang can do all of these, it's got a little something more regarding design patterns. There are a few very common roles that most Erlang processes will respect in their lifetime:
- servers are worker processes that hold some state and answer to a bunch of requests as they come in (returning DNS data could be done by a server, for example)
- finite-state machines are worker processes that will react differently depending on the state they're in and what has happened so far during the execution. They're usually the sign that someone's implementing a protocol or implementing some kind of agent that behaves differently based on its state.
- event handlers are sets of functions to be plugged inside a worker process that acts like a message hub. This is similar to the common event callback model used in asynchronous frameworks like twisted or node.js.
- supervisors are processes in charge of monitoring what other processes are doing, and denote a relationship between them, as described earlier.
You'll find that most patterns ever possible in Erlang tend to fit one of these four categories rather well. They all have a behaviour attached to them (gen_server, gen_fsm, gen_event, and supervisor) which gives them all a uniform interface.
The point is this simple: where most languages have their design patterns being rather ad hoc (how many different factory patterns or singleton patterns are implemented from scratch in a project?), OTP makes it so that everyone uses the same implementation for all patterns, across all projects.
There is very little work that needs to be done to understand, at a high level, what a worker will be doing, what its role in the system will be. This is likely a very huge part of why people feel OTP reduces the amount of time they need to be comfortable with a code base.
Take any system, and if you see a gen_server behaviour, you know that this process will be organized in 3 parts: its interface (how other processes or modules will call the server), the server callback functions (how you dispatch messages received) and then private functions implementing more complex business logic, if any. And of course, you know the server will have a server-like role.
Compared to other languages, this is somewhat similar to having higher level interfaces or protocols that are used by everyone, everywhere, with very little conflict, if any.
4. Everyone uses it
This brings me to the point of everyone uses it. It's not necessarily obvious that this is an advantage over anything else. Who cares who uses a framework or a language? It's Erlang! Nobody uses it anyway! That's a fair counter point. I do maintain that it's an advantage.
Nearly all the libraries you'll find online will support or at the very least play very well with 'the OTP way'. Compare with asynchronous frameworks like Node.js or Twisted Python. These frameworks support paradigms or are based on ideas that do not necessarily mesh well with the material outside of their community, but still within their host languages. This means libraries from the general languages cannot always be reused in the framework because they will clash in their respective models or paradigms.
Erlang's OTP is a logical continuation of Erlang's own principles. There is nearly no friction between the two levels. This general compatibility guarantee means that if a given web framework has developed a logging tool I would like to incorporate in my project, I'll likely be able to do so without a problem, even if I'm currently logging stuff for a test framework in charge of doing black box testing on one of the many computers in a car (assuming they at least have somewhat similar requirements). It will be the exception when someone writes a library you can't add to your project because its paradigms clash too much with the ones you're using.
It also means that when tools are improved by someone in some area of the industry (or academia), everyone else benefits from it. It creates a positive feedback loop where people want to improve tools everyone uses, so more people use them and the tools can get improved more. I've written blog posts before about idiomatic code often being the best in Erlang, and I hold the belief that everyone using and improving the same set of tools has to have its weight in there. You don't improve things out of competition between frameworks, you improve them in a common effort.
5. Further support for Reverse-Engineering
Sometimes, the complex interactions between many components of a system, especially when concurrent, turns out to be a real hell hole. Sequential programs can often be reasoned about as a list of actions happening one after the other. Concurrent and parallel programs will require you to have as many lists of actions as actors, which can all be combined differently based on entirely non-deterministic factors. It's bound to be messy.
At this point, reverse engineering starts becoming difficult. Debuggers won't work because they will, by their own presence, alter the way the system works and mess up with the timing of things. Print statement debugging may serialize actions in a way that hides a bug that happens at run time. The tools you're used to no longer cut it.
Fortunately for people maintaining OTP systems, all OTP workers are fully inspectable and traceable. A call to sys:get_status/1 will return the process' internal state, where it comes from, a short description of what it is, and so on. You can thus take snapshots of workers whenever you wish.
By calling sys:trace(Worker, true) on a process implementing an OTP behaviour, you order it to start noting everything that happens. You can then see all inputs and outputs related to the process in real time, even in a production system. No need for special compile flags or anything. Set it on a bunch of workers and you can get to see how they interact together. More than that, you can turn the tracing into logging (to a process, or to a file), or register your own tracing function on a per-worker basis to get more fine-grained control, or to program processes to do trace-monitoring for you! You can also suspend, change the code of a worker, and resume its execution through the sys module.
That's good, but in some cases, it may not be good enough. Sometimes OTP is not providing what you need and thus you go lower. At the VM level, nearly everything is traceable: when a process calls a given function, when the function returns, when it gets garbage collected, when it gets scheduled or unscheduled, when messages are sent or received, and so on. There's as much flexibility with it — tracing can be done over multiple nodes, across a network, and you can log to files, sockets, or other processes. You have to be careful though, because there is so much information available that not being careful with the tracing functionality can easily crash a production node by overloading it. Handle with care.
Conclusion
There's still stuff that makes it hard to grow Erlang products. The first and most annoying one likely the inability to have multiple versions of a single library being used at the same time within a virtual machine. This causes an overhead in effort made to keep your software stack working. I'm not sure how it can be fixed, and it seems like most of the OTP guys at Ericsson (and outside of there, too) are scratching their head just as hard as everyone else about it.
The other tricky one is the issue of namespacing. Erlang has no namespacing, so programmers tend to do the ad-hoc prefix_ stuff to all their modules, ETS tables, registered processes, and so on. It's easy to miss one or two of them, and namespace clashes definitely suck. I find them rare in practice because the community learned to cope with them a while ago, but that's because of discipline, and discipline is unreliable.
That being said, Erlang developers who answered my poll definitely seemed to think OTP greatly helped them, and gave them confidence in how soon they could claim to own a code base:
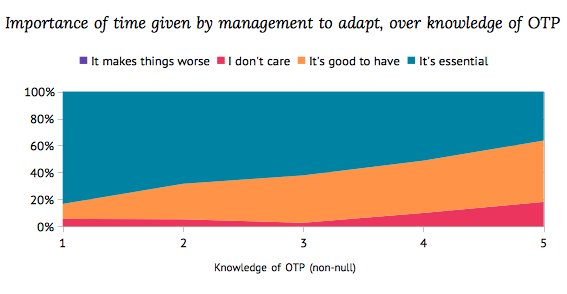
The more OTP you know, the less time you expect it takes to adapt to a code base. Clearly there's something about OTP. Here's what it likely is, put shortly: the common structure of OTP behaviours and applications tends to give some stricter modularity constraints to a system, on top of wrapping common behaviours under very well known patterns. This makes it easier for the developer to dive in a code base, play around it, and modify it without requiring a deep knowledge of all the other components of the system. This is likely why Erlang developers judged OTP as essential. There is some definite value in using Erlang to make maintenance easier, less annoying, more fun.
I hope this post offered some insights in what Erlang can offer for you to grow a software system, and how it could change the pain of maintenance into a mild discomfort at worst, tending to your garden at best.
[1], [4]: Programs, Life Cycles, and Laws of Software Evolution, MM. Lehman, 1980
[2], [3], [5], [7]: Software Maintenance, Gerardo Canfora and Aniello Cimitile, 2000 (PDF)