Handling Overload
This is a long-ish entry posted after multiple discussions were had on the nature of having or not having bounded mailbox in Erlang. The general consensus is that this is bad because the mailbox, if unbound via the language, are therefore bound by memory limitations of the computer, and all control is lost (this is no longer true, since OTP 19, added a max_heap_size flag that can be set per process to force an early death if its memory usage is too high, including its mailbox).
In this text, I'm going to dig through the common overload patterns that can be encountered in Erlang with the regular workarounds available today for your systems. Do note, however, that the overall criticism of flow-control remain true in other concurrent platforms, specifically the preemptive ones such as Go. Cooperative ones (like Akka or node.js) will tend to have implicit mechanisms due to heavy workload blocking the CPU earlier, but may still encounter the same issues depending on workloads.
Background Info
I'm gonna try to go at it from a fairly generic manner, but to do this, I'll have to establish a few concepts.
Little's Law
The long-term average number of customers in a stable system L is equal to the long-term average effective arrival rate, λ, multiplied by the (Palm‑)average time a customer spends in the system, W; or expressed algebraically: L = λW.
This essentially says that what really matters to the capacity of your system is going to be how long a task takes to go through it, with how many can be handled at once (or concurrently) in the system. Anything above that will mean that you will sooner or later find yourself in a situation of overload. Increasing capacity or speeding up processing times will be the only way to help things if the average load does not subside.
Backpressure
Mechanism by which you can resist to a given input, usually by blocking.
Load-shedding
Mechanism by which you drop tasks on the floor instead of handling them.
The naive and fast system
The naive and 'fast' system is one where all the tasks are done asynchronously: the only feedback you get is that the request entered the system, and then you trust things to be fine for the rest of processing:

You can only know that things worked by looking at changes in the overall system, or streaming logs. Otherwise, all is feedback-free.
Now it's possible that the input and output bits are made synchronous by the observer, which could poll for system changes until the desired modifications are noticed. Even then, the internal flow of information would still not be synchronous. If the 3 transforms above are processes, any level of concurrency on the system may look like:

This generally would mean you get quite the linear scaling going on, and each incoming request can be allocated all the resources it needs; capacity is fairly easy to predict by little's law and rating your system for a maximal capacity is simple. A harder scenario is one of those that tend to happen in the real world:
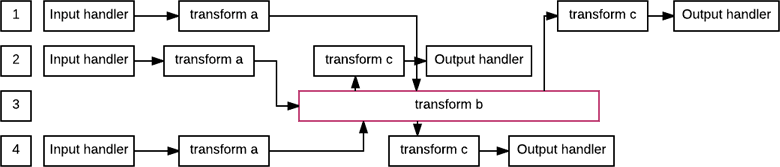
because the process in charge of transform b cannot be parallelized, it is a bottleneck, and the flow of all tasks depend on its success and the average sojourn time of a request through the system shoots up.
Because the sojourn time shoots up, a continuous influx of requests to the system can increase its load (each request making things worse for all other ones) until the system runs out of memory and fails.
That's when people complain of the need for bounded queues in Erlang: process in charge of transform b could be configured with a max queue size, which would then drop or block and fix our problem.
The unavoidable backpressure
By default, people tend to think of control flow as blocking first; there tends to be far more cases we can intuitively think of where "late is better than never", and therefore, forcing requests into a waiting line makes more sense than just shedding load by ignoring and dropping them.
Back-pressure is actually the default way to do things in most programming languages, since function and method calls are inherently synchronous in most cases. You only move forward or return once a computation has ended, and if there is contention, the overall systematic symptom is that things become slow.
This, of course, remains true in Erlang, but only as long as all the calls for a given request happen within a single process. Then, the regulating factor for all the requests is how much concurrency can be had by design or limitation.
In such a system, if your server is able to handle 500 concurrent requests and then it stops accepting more, that's how much load you can plan for. You get an easy upper limit. Few servers, whether they be web servers, socket servers, or whatever kind, will tend to impose a limit, even though it can be done: we all like the idea that we can scale linearly and are not happy with the idea of a known low-level of concurrency being in place for the sake of stability. Indeed, it'd be way nicer to get our stability through less drastic means.
The case of a perfectly parallelisable system is fairly trivial to handle, still: benchmark until you hit a breaking point, put a hard limit on concurrency (make the whole server a pool), and then scale horizontally by adding more servers. This case is not very interesting to handle system-wide because it is fairly rare, but it is still going to be valuable for subcomponents of the system or as part of some optimization (concurrent connection pools come to mind here).
How to handle this in Erlang
Most pooling libraries offer a simple way of doing this, and many offer fancier control than what would otherwise be available:
Note that I am omitting pools more adapted to specific tasks, such as those dedicated to network clients or database connection handling. There's probably more generic pools than only those shown here.
The naive backpressure
In the case of Erlang, asynchronous is the default as soon as we introduce multi-process communication. Given the more complex diagram from earlier:
Process 3 is going to be at a risk of getting an overflowing mailbox if other processes on the node send too many messages its way.
The easy way to fix this is with backpressure, by making all calls to process 3 synchronous. This means that whenever processes 1, 2, or 4 send a message to process 3, they won't be able to send another one until process 3 has responded to one of theirs because every one of them will be stuck waiting for a go-ahead signal to send more.
Instantly, this limits the amount of concurrent work possible to do and prevents overflow by slowing the system down.
There's a fatal flaw in this reasoning, however, and it is that very often, our system design does not account for these implicit limitations. Instead of seeing the workflow in terms of pipelines, we see it in terms of steps:
- accept a request over a given protocol (HTTP, TCP, UDP, etc.)
- parse the request (and do authentication and authorisation and so on)
- send the request down to some worker processes or ask a worker processes for a resource required in processing (these processes can in turn call other subsystems with their own backpressure and load-shedding mechanisms!)
- format the response
- send the response
- publish logs and metrics
This approach makes sense, but ultimately, the problem we face with it is that its (entirely desirable) decoupling also tends to decouple the processing flow from its sources: the processes accepting external requests. This is either done through concerns about clarity of implementation, or just usage of libraries which, by design, tend to want to be self-contained.
The problem then becomes simple: the limitations of a worker doing data processing or interacting with a data store are disconnected from the concurrency limitations of the request accepting and parsing. This disconnect then results in disjointed backpressure mechanisms:
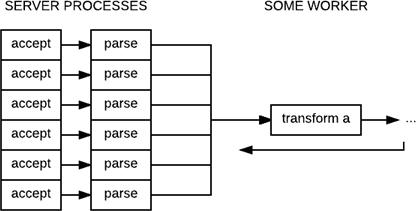
And just like that, even though there may be back-pressure between any of the server processes and the worker, the constant flow of new incoming server processes is enough to kill the overall system. In such a system, a limitation on the amount of concurrent connections is still required to prevent workers from overflowing, but as you add more and more workers, limitting resources implicitly will become more difficult. For example, it's easy to conceive the idea that not all requests have the same cost, and while 90% of them may take 1 millisecond to handle, 5% may take 5 milliseconds and the last 5% could take 250 milliseconds.
This creates an imbalance where you either have to be overly pessimistic and really throttle more than you need to prevent a worse case scenario (90% of tasks take >250ms, for example), or take an unsafe, but more permissive approach. The latter is usually chosen.
This will be a reality in mostly any concurrent language out there that relies on synchronous back-pressure to solve their problems, but specifically those with pre-emptive scheduling where the workers cannot easily saturate the CPU and prevent server processes from doing further accepting, whether willingly or inadvertently.
How to do this in Erlang
Just use synchronous OTP calls in
gen_*behaviours for all desirable interactions
Pull-based control flow
An interesting workaround done in many stacks and languages (Elixir's GenStage comes to mind, but similar patterns exist in many places) where work to be done is represented as a set of 'pull' or 'consume' operations rather than a set of 'push' operations or messages:
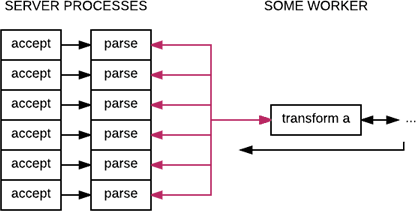
The diagram still looks the same, but instead of all server processes knowing about the worker, the worker knows about a pool of server processes from which it is allowed to consume data. However, the problems you may encounter with this approach are the same as you'd see with a synchronous workload, namely that the disjoint limitations between the number of accepting processes and the consuming ones may result in overload and overflow.
Do note that flow-based processing still has interesting advantages and properties, but it will mostly do so when a restricted set of producers exists, and that they can create a lot of data that they can control.
A good example of a thing they fully control may be the parsing of a file on disk or a data dump; introducing lines in memory to process them is done very well in a streaming fashion. Reading from another stream (such as a Kafka stream) also makes sense there. You'll notice that in both cases, it is essentially trivial to pull from an initial source without interfering with its semantics.
If the resource is not a controlled one, and is mostly push-based (such as a TCP socket for example) the system will be harder to make stable. We have to start considering it at a wider scale:
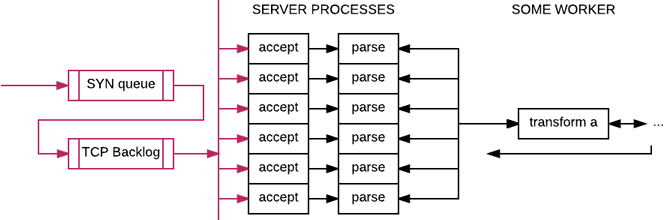
The incoming data comes from remote endpoints, which fill a SYN queue. The SYN queue is used to handle pending requests to create connections by the linux kernel, which are then handed over to the TCP backlog. The TCP backlog will hold connections until the user program calls 'accept' on the socket, and will then hand it over to the program.
Such buffers, when not tuned properly (or when users are not aware of their existence), tend to handle overload by either denying requests or dropping them on the floor. This pair of buffers turn out to do both:
The TCP backlog will deny further requests, and will keep the existing ones in memory. This can create fun cases where a request is seen as 'sent and accepted' for a long period of time by the sender, but never actually seen by the consuming program. If the sender gives up after a timeout, the kernel may then close the connection and drop it off the backlog without further notice to the server processes in userland. This is often the cause of 'ghost' requests, which are known to be sent and accepted by the sender, but never logged by a server (unless someone is looking at tcpdump or specific system metrics at that moment).
- The SYN queue may freely discard the incoming SYN packets by default (it can be configured to block new connection attempts). This will then rely on the client's TCP stack assuming lost packets and retrying again in 1 second or more (the minimal TCP delay in linux for a retransmit is 1 full second).
This is going to be particularly nefarious because metrics will usually be gathered by the server software in userland. Meanwhile the slowness will only be detected by callers usually outside of your system, and everyone will be scratching their heads trying to figure out why people are complaining. That is, assuming you have decent metrics to begin with.
Other stacks, such as using UDP, may instead just suffer lossiness, but I assume that if you're using UDP, you're ready to deal with that.
It would be a mistake to build a system without considering these queues as part of the control flow; anything under heavy load where it hasn't been considered will sooner or later have to debug them, and whereas the application server will look extremely healthy, the overall system will be slow and lossy in ways nobody can easily debug. Overall visibility has been lost.
There's no clear solution for this one aside from "hoping the system is fast enough", other than adding some layers of indirection.
How to do this in Erlang
Erlang itself has few mechanisms for pull-based workflows in the community that have been adopted largely by everyone, but plenty of libraries here and there to do it:
- erl_streams for an approach similar to what many languages use for stream processing (actors doing a pull-based workflow)
- goldrush for a different, more functional- or compositional-feeling approach
Bounded queues
A simple way to handle the problem and get more visibility is to bring all the data inside the system as soon as possible and chuck it into a bounded queue; the previous bits of the TCP stack are in fact implementing just that.
The important distinction between a bounded queue and synchronous communication is that the bounded queue gives a fail-fast mechanism to deal with overload.
Synchronous communication will just silently block, and giving up on a task may make it hard to purge it from the system. The resources can easily grow unlimited in usage if the producers are not strictly limited by the waiting and blocking of the process they contact.
Instead, bounded queues let you know when a buffer is full, and a decision can be made between dropping a request, or returning 'nope sorry, I'm busy' back to the client (back-pressure). The operation to enqueue is synchronous, but it is expected to fail earlier and much faster when the queue is full.
A system with a bound queue may look like:
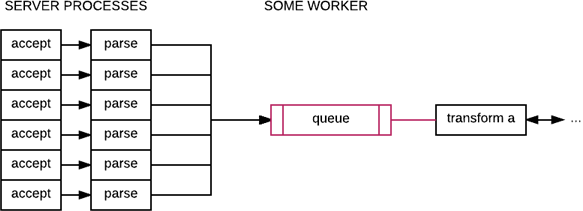
It should be noted that the communication between the transform and the queue can be either a synchronous push or a pull mechanism without any major impact on semantics in here.
What quickly becomes critical however, will be how the queue is implemented. In the case of a server-side stack like Erlang, it may be interesting to use a process as a queue, but it will suffer the same problem as any other worker: the work that can be done by the queue process is quickly as limited as the work for any other task.
Even if you strictly optimize the process there, you may sooner or later hit limitations. If you're running on a 4 cores boxes, it may be okay for the queue worker to peg 1/4 of the cores to do limitations and let the rest of the work go elsewhere. The practical amount of resources obtainable for that process diminishes rapidly if you move to servers with 16, 32, or even more cores though, and rapidly you may hit harder limits. The producers can be fast enough to flat-out beat the work done by the queue worker.
This in fact becomes a bit clearer in the case of Erlang when you use distribution. The socket used by distributed Erlang to talk to another given node is using a limited buffer, and implicit limitations of bounded queues existing and shifting around the system rapidly become confusing.
To fight such patterns, two solutions are generally offered. The first one is to have more queues and dispatch through them with some form of hashing. This will allow to spread the load across cores and processes, although you may get to fight hotspots and whatnot over time.
Otherwise it is usually recommended to instead use something like an ETS table as a gatekeeper; the ETS table will contain a single counter for a given queue, and processes wanting to insert messages in the queue can then make an atomic write call with ets:update_counter functions with an upper-bound on the max queue size. Only the queue consumer can decrease the counter, and if the max is hit, the server processes (producers) flat out refuse to enqueue the task.
This ends up being a much stabler pattern just because it is cheaper to do that operation than it is to copy the message from a worker to the queue process, transfer the message from the mailbox onto the process heap, and then possibly shed it or return a message back denying its processing, and then doing garbage collection for it.
How to do this in Erlang
There's very few queueing libraries offered in Erlang directly; for the most part, people will use the mailbox as a queue, or more advanced tools to be discussed later. Still there's a few:
- pobox with a specific focus on batching and load-shedding
- sbroker supports some simple modes that make it work like a bounded queue
- some of the previously mentioned pool libraries often also include a queue
- other interesting approaches would use a library like pqueue and consume messages as fast as possible in a priority queue in memory
Hashing can be used to just split work evenly, a few being:
erlang:phash2/1-2to arbitrarily hash any Erlang term (such as a pid) to do a dispatch to many workers- lrw for 'lowest random weight' hashing for stable interfaces
- jch for 'jump consistent hashing'
- chash for Riak's consistent hashing library
Counter and locking solutions tend to:
- just use
ets:update_counter/3-4to maintain lock values - canal_lock for resource-adjustable dynamic locks for dynamic resources
- some of the pooling libraries mentioned above contain such mechanisms
Counter-protected process
The interesting bit with a bounded queue and the usage of mailboxes for processes in Erlang is that the queue from the previous section stops being required. We can go back to:
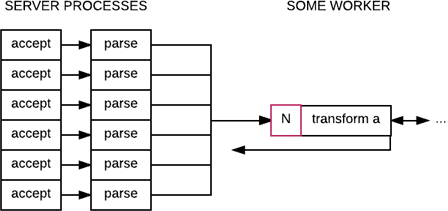
As long as a given server process accesses the counter (a mutex!) before sending its message. In fact, that's probably how one would naively implement the queue from the previous section. The reason it's interesting to think of the counter as protecting a mailbox instead of a queue is that it lets us think about it as agumenting a process instead of adding an architectural component.
Would there be value in putting one of these at every step of the way?
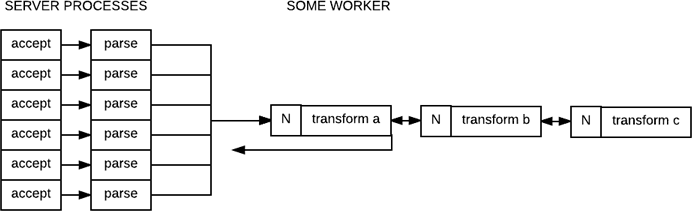
Technically, there would be little value in doing this, simply because if the first worker is doing synchronous work with the latter one, then the synchronous aspect of execution means that a single counter (and therefore a single point of contention) should be sufficient to protect the entire pipeline; otherwise, the reate at which A can dequeue will be related.
This will not hold if operations between any of the workers become asnchronous again, and the same criticism holds for queues:
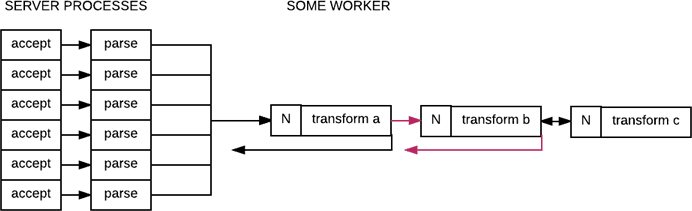
If the communication from A to B is asynchronous, then the counter protecting A is mostly useless to help with total system stability: it prevents A from having its mailbox overflow, but B's own counter would have to do the same on its own if it is slower, and since B depends on C, then B implicitly protects C. Now, the counters in A and B are all possibly very useful.
Things get hairier to track when the messaging process is not a pipeline, but a graph of multiple processes that are mostly disorganised or into independent structures. Not only is ensuring good system balance tricky, but we now introduce all kinds of possibilities and asymmetric delays where parts of the system are clogged but not other ones, and if data crosses streams between subcomponents, part of the pipeline can be super healthy while other bits of it a crawling with pain.
What transpires from this tought exercise is that the things we need to protect are:
- all points of asynchrony that prevent direct feedback via messages
- patterns where ever-increasing senders can effectively cancel the result of direct feedback via messages
- having a ton of queuing points makes it very hard to reason about the system
This is interesting food for thought!
How to do this in Erlang
- just use
ets:update_counter/3-4to maintain lock values - canal_lock for resource-adjustable dynamic locks for dynamic resources
- some of the pooling libraries mentioned above contain such mechanisms
The Network Plays Ball
In fact, this problem is specifically what happens in large networked applications when people go "the thing is slow". We have this constellation of networked services routed over multiple physical devices.
The difference for a networked service is that there is no such thing as a big "node-global shared mutex or atomic counter everyone can hook into" to synchronize things; everything is made much harder because it is done as an observer. In short, the network brings us back to early design decisions because we're stuck with message passing and nothing fancier.
What could be done?
Well, a lot, actually! To make a gross oversimplification, networks will rely on a few mechanisms to keep working, such as:
- out of band signaling and messaging to communicate about health (i.e. ICMP messages)
- estimation of quality of service via observation of in-band messages
- adjusting of scheduling and sending of messages according to 1 and 2
A quick note there is that observation of in-band messages, such as going "oh, things are starting to take a lot slower than usual, I bet something iffy is going on, better slow down a bit", intimately require respect of the end-to-end principles. Doing them hop-by-hop tends to be an exercise in frustration, specifically because you end up with a lot of challenges similar to those we see with processes within a single node. Being able to insert probes at the beginning and at the end of the pipeline tends to let you take a snapshot of the system health in a simpler way. If you have synchronous communication channels (and therefore the sender receives feedback from the entire pipeline as it receives its response back -- or does not receive it), then the sender can be your back-pressure mechanism.
For a lot of server-side software though, the overall consensus is that you cannot trust clients, or at least not all of them. What you can do instead is have a kind of middle-man component that will take client requests, and then forward them to the rest of the cluster in a more trustable manner.
Related Reading
Applying to Our Systems
It would be a bit difficult to port all of the expertise embedded in the world's networks into our application layer stuff and make effective use of it. It's mostly impractical and the problem space is huge. What is interesting in borrowing from networks (at least one of the many things) is the idea of probing for quality of service and adjusting behaviour accordingly.
The tricky aspect of probing for performance is choosing how to do it; given all tasks in a system are not equal (some take longer, some take shorter) except in rare circumstances, probing at the beginning and then the end of a request (the total duration) is not a practical metric.
A more general mechanism for that will often require to rely on a queue being used, with a probe put at either end of the queue:
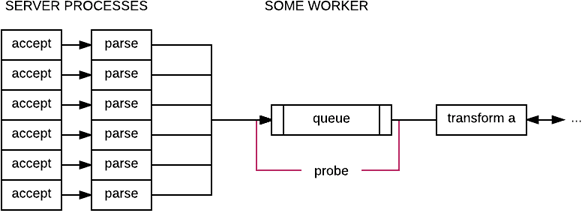
What the probe will do is calculate the sojourn time of a given task within the queue. Unlike the duration of a single request, tracking the time in the queue gives an instant overall wait time within the system based on its capacity to extract any number of tasks from the queue.
The system can then be configured with a way to adaptively handle a queue filling up with increasing sojourn time: the longer the sojourn, the more overloaded the system and the more constrained it should be.
- if we aim for a low overall latency for newer request but don't care to have long waits for some (i.e. phone call systems for support often deal with this) turning the queue into a stack automatically helps
- provide an upper timeout; all requests that have waited more than a given period of time are considered stale and dropped (load-shedding)
- prevent enqueuing requests when the sojourn time is too high (back-pressure)
- randomly drop requests within the queue with increasing aggressiveness as sojourn time increases (load-shedding)
- randomly drop requests before enqueuing them with increasing aggressiveness as sojourn time increases (back-pressure)
- implement the CoDeL algorithm (works well with multiple queues in a system)
Things to note here include that the idea of load-shedding tends to require that either the workload being sent is possible to ignore and lose, or otherwise requires client-side cooperation to eventually retry failing operations; the idea there being that we assume that eventually, the system will have enough capacity to do its job. There are cases where this will not be true, although they may be rarer overall.
The other thing worth mentioning is that randomly dropping requests is a much more complex approach than what could initially be believed. Even though it's possible to implement very naive and functional versions, algorithms like RED, MRED, ARED, RRED, Blue, PIE, and so on, all more or less include small but important variations in how the random rate is calculated and modified to account for metrics.
CoDeL is a bit of a special case in that it essentially requires no configuration. It can be used both as a back-pressure and load-shedding mechanism depending on whether you wait on the acceptance of the task and the specific implementation used is able to notify you when a specific task has been dropped off the queue.
These systems tend to be fairly interesting for a lot of tasks, but as for before, having the ability to insert random asynchronous points in a pipeline can accidentally undo work.
How to do this in Erlang
The following libraries implement various of the above mechanisms:
Capacity Probes
When you get to all these issues, it starts being interesting to simply ask the question: can I force a reaction or shut down in my system when some key metrics are too high? For example, can work be dropped when memory gets high, when CPU usage is too important, when we detect that send buffers for the network get filled, or that database pool capacities are exhausted?
Of course this is doable. Some of the metrics are more general and shared across applications (CPU, memory, scheduler usage, and so on) and some are very specific to current apps (pool usage, specific API failure rates, etc.)
This gets to play in the specialty of multiple components, specifically circuit breakers and work-regulation frameworks that allow sampling.
The former case is simpler to understand. A circuit breaker is basically a gatekeeper to some operation that will track a given metric: failure rate, timeout delays, and similar metrics. When a failure rate judged to be too high is detected, the circuit breaker instantly prevents specific operations from taking place and returns an error instead.
They can be thought of as components that work as efficiently as counters, but work on a different metric than a maximal value.
A naive circuit-breaker usage may be, for example, to say that if a given call to a web service fails more than 3 times in 10 seconds, we assume it's down and prevent all attempts for 5 seconds. We could also say that if it takes more than 750ms to get a result back, we consider the remote service to be busy and consider such a call to be a failure.
Circuit-breakers are a very important component of building stable systems, but what is interesting is that they often allow a mode by which you can manually trip the breaker; for as long as you desire, the incoming calls are seen as forced to fail. The reason this is interesting is that we can use this property to build probes and agents that will control certain breakers. Then, by looking at all the breakers when entering the system, we can know if it is worth scheduling a given task or denying it:
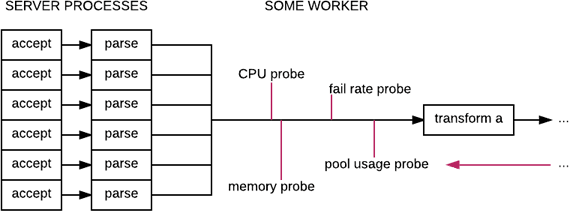
By putting the probes in place in all critical areas of the system or on key metrics, we can then cut and trip circuit breakers as we see fit. This lets us create surprisingly simple and efficient mechanisms by which we can be allowed to have parts of the system become asynchronous and bypass common mechanisms, as long as the consequences of overload deep down are somehow captured by one of the circuit breakers.
In the case of ever-increasing mailboxes for example, memory could easily play that role.
One caveat of using circuit breakers though is that they tend to be an all-or-nothing mechanism. Their use can therefore create flappy systems that will react somewhat violently to probes melting fuses. A simple way to try and work around it is to use queues as a dampener: put the probe checks before the queue as a kind of barrier (the last of which could be a queue size, to include the counter approach!), and as the queue gets drained through blown fuses, their individual effect becomes more like a regulator than a full stop. They will be a perfect match when the cause for a failure is pretty major, such as a remote service being entirely down.
A more systematic approach to resolve that is the one seen in the jobs framework. Rather than manually installing a bunch of circuit breakers, the queue for the overall system can see its limits and inputs augmented by samplings of various metrics (once again, such as CPU or memory).
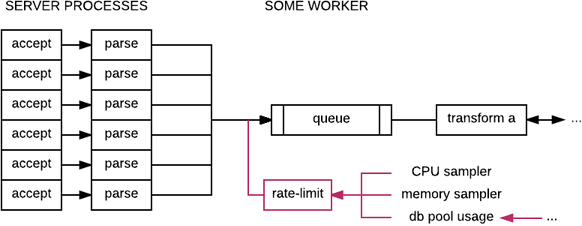
What the framework will do then is use the samples taken from various probes around the system, and use them as a weighing mechanism to choose a rate at which the job queue may be consumed. As consuming of the queue is modulated by these metrics, it may be allowed to fill up to a point where requests are directly denied.
To add to this, such frameworks will typically be employed at the edge of the system, not throughout. By being able to take into account various internal metrics and characteristics of the system, we can get a general configurable policy in one spot, which then protects the rest of the system, allowing for a clearer implementation for the rest of it (where you may actually encourage asynchronous behaviours!)
What's interesting is that both approaches are not mutually exclusive. Circuit breakers are usually extremely cheap to run and check, and so combining them with another approach is a great way to preserve overall system balance when major failures happen in upstream components and services, a case where the guaranteed failure of the operation would likely be much more expensive to account for within the queue management frameworks themselves.
How to do this in Erlang
The most commonly seen circuit breaker libraries are:
- Klarna's circuit_breaker
- fuse
- breaky
And the one tool to do full blown job management there is Ulf Wiger's jobs framework.
Conclusion
There's a lot of possible solutions for all kinds of tasks and workloads here. What I hoped to show with this text is that there is a rich zoo of overload problems and potential solutions that can be applied to solve them, ranging far beyond a simple queue boundary for mailboxes. By reasoning and looking at your system, it becomes interesting to figure out which approach is best: a small system with some relatively infrequent load-spikes may be fine with a queue or a pull-based mechanism. An all-synchronous system may be fine with simple counter-based protection for most tricky cases.
Complex systems may, on the other hand, require a more involved approach, especially when analyzing the overall workflow is complex. The solutions can range from active queue management to gathering all kinds of metrics or probes and enriching the scheduling or regulating mechanisms of the system with them. They can also be combined together to produce very performant solutions without requiring titanesque effort.
Thanks to Jesper Louis Andersen and Evan Vigil-McClanahan for reviewing this text.