RTB: Where Erlang BLOOMs
I'm still on my way back from the Bay Area Erlang Factory 2012 (in fact I finished this post after coming back entirely), in San Francisco, and I've been starting to see a bunch of twitter posts regarding people posting their slides online. Although it is a good idea, I tend to view my slides as pure visual support, and the animations don't show up very well in a static PDF, so I thought I'd do a quick transcript of the main ideas that were at work in my talk, Real Time Bidding: Where Erlang BLOOMs, as brought to you by BLOOM Digital Platforms.
Types of advertising
When advertisers want to buy advertisement, they can do it at large on some user group and hope to get decent results, or participate in Real Time Bidding (RTB). In RTB, advertisers bid on individual advertisement spaces to obtain more targeted audiences. This is usually built on the backbone of large exchanges where bidders require high performance, short response times, and a high volume.
More precisely in the context of the Internet, the traditional way to do things is called display advertising. It's the general practice of having website owners contacting some advertisers or an adgency that just pushes advertisements on the said website. This can be done broadly, where you have deals for a dealer to send a bunch of ads that always change on your site, or in more precise cases, where you have deals with specific advertisers. One example of the latter is Microsoft, who before Windows Vista came out paid some people up to CDN $80k per week to have some websites change their background to something pro-Vista.
Real-Time Bidding (RTB) is a kind of evolution on top of display advertising. It is a bunch of loosely defined protocols employed by nearly as many exchanges, who allow that, instead of dealing with a single distributor that has a limited inventory of ads, anybody can try himself on buying advertisements in soft real-time. Here's what an exchange looks like:

So let's say I'm a car dealer. I've got a website. From the user perspective, whenever they visit my page, they see a little snippet of HTML or Javascript that contacts a server:
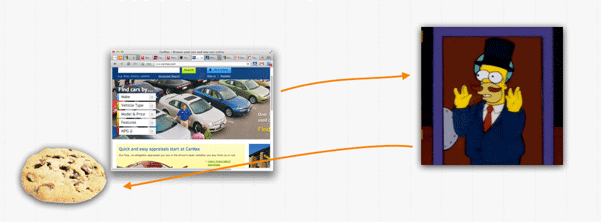
Optionally, the display advertiser places a tracking cookie on the site, so they're able to do things like calculate various conversion rates, or just make sure not to show the same thing to the same browser too often.
When it comes to RTB, things begin the same way, but once the request for an ad makes it to the exchange, that exchanges sends something called a bid request to a bunch of bidders. These bidders all represent one or more advertisers, or can themselves be exchanges that aggregate requests from many exchanges and forwards them to bidders. The bid request will often contain information such as the kind of site the user is visiting, and other general information such as geographical location, age, etc. if it's available. In any case, the bidders (in the case of ours at BLOOM, it's called adgear trader) try to decide, with the help of such data, whether or not they want to advertise to that person.

When a given bidders bids, it does it by sending a snippet of HTML or Javascript (depending on the exchange). The winning bidder then has its snippet displayed on the page by the exchange (which can update its own cookies at the same time) and then pushed on the page. At that point, the bidder can then set its own cookies and do its own thinkering:
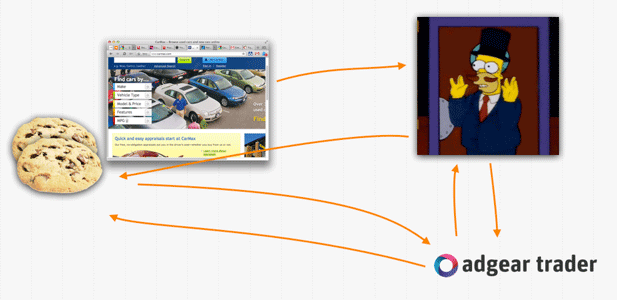
There is also generally the practice of cookie matching which helps share anonymized data between different actors, making the general decision process better. In our case, it's done in C, directly in an apache module.
In any case, there are types of campaigns made especially interesting by RTB. Say I'm still a car dealer with a website, but now I book a deal with a given bidder so that I can also advertise online. A given user visited my site with that bidder and thus got cookied (or was tagged through some deals). When that user visits another car dealer's website, expecially if it's in the local area, I now have a chance to put advertisements on that site. I can thus bid more money on the auction in the hope of winning it. Then if I win it, I can just finally display my ads, update my cookies, and so on:
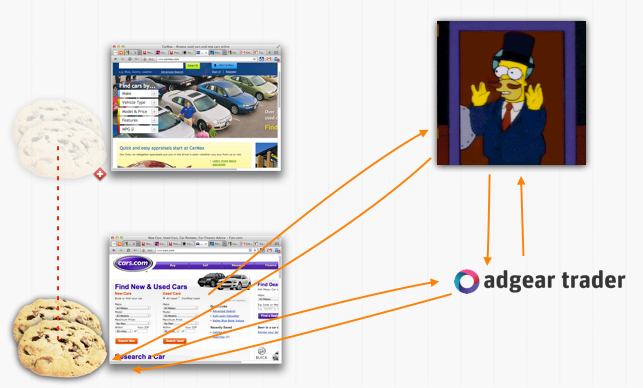
And ideally, we bring the browser back to our shop!

The Gateway
The product we're working on related to real-time bidding and Erlang at BLOOM is the AdGear trader, which sits in between a bunch of bidders, and a bunch of exchanges:
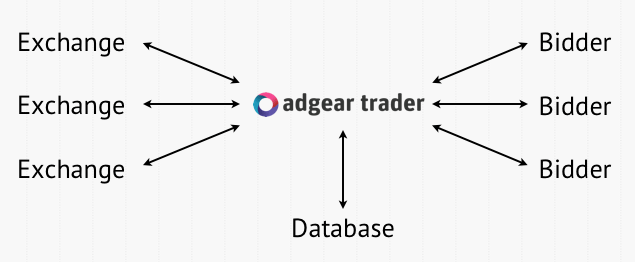
The gateway is running on (so far) 6 servers, with 16 to 24 cores and 16GB of RAM (although each instance of the gateway usually takes less than 5% of that. They're all running Linux Gentoo (I think you mean GNU/Linux), and we make use of Cassandra and Redis in terms of databases. Each gateway instance gets thousands of bid requests each second, usually between 4,000 and 9,000 depending on the period of the day. Most of these requests are then forwarded to many bidders at once, received back, and a reply gets sent — the gateway acts a bit like a small exchange aggregator.
Latency is pretty important, given that we usually get around 35 milliseconds to handle each request, although that value tends to grow with more recent developments. This includes delays for parsing the bid requests, doing some searches in the database(s), serializing a bid requests and sending them to clients, waiting for a response, parsing said response, picking the best bid of all our clients, encoding it in the exchange's format, and pushing it back there. Ideally, we want to do all of this without skipping a beat, and because we also handle things like serving a javascript tag that tells us when we won a bid, we need to have as little downtime as possible (ideally none). This is because knowing we won a bid lets us increment the allocated budget for some campaign and that way we make sure we're not spending a trillion dollar.
We've got to Scale!

Well of course, scaling is nice, but the first thing we have to do is measure, measure, and measure some more. Our tools of the trade there are Graphite, StatsD (a node.js frontend to graphite), statsderl (client for StatsD), a bunch of manual calls to statsderl, and vmstats, which pushes an Erlang VM's details to StatsD.
What we obtain with this is a series of graphs that we can customize and make look a bit like this:
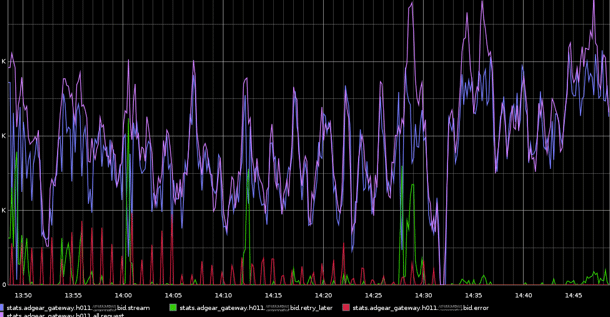
This reveals the first problems we had. On the left hand side of the graph are all these large green peaks and red bumps. Those are caused by the ibrowse HTTP client library. It's the first one we used to have running: it has a nice load-balancing feature and supports an asynchronous mode. The problem with it was that from time to time, the load-balancer would lock-up by forgetting to release resources. This would cause the green peaks. When that'd happen, all requests would stop being forwarded to bidders.
The red peaks were the consequence of us basically restarting ibrowse every minute or so. The thing is we were short on time to fix ibrowse, so a suboptimal, temporary solution was taken. Eventually, we had the time to fix it. We picked lhttpc as our library of choice (it also supported asynchronous requests), and then we made our own load balancer for it. When we deployed it, you saw what happened on the right-hand side of the graph: peaceful functionality.
The load-balancer we wrote for that one was based on the idea that we have one load-balancer per domain, which is to say one per bidder. The load balancer keeps a list of N sockets always active. Requests coming in then just send a message, ask for a socket, and do their thing before returning it:
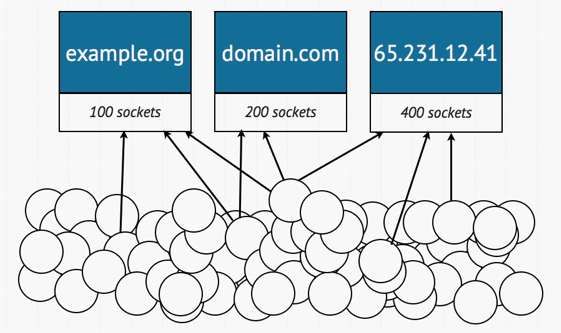
This makes sense for a few reason. First, we want to keep sockets always open because setting up new connections is mighty expensive. If it takes 7 or 8 milliseconds to get one going, this could be 25% of our processing time for each bid request. Keeping sockets open is a no-brainer. Next, there's the idea of having one load-balancer per domain. This is necessary for a few simple reasons. If there is one bidder that twice slower than any other one, it is unfair for that one to hog all the sockets available. Moreover, it is imperative to be able to divide the requests between many processes.
Let's say we made the bad decision of having one load-balancer for the whole node, and I have three bidders. For each bid request I have, I might then send 3 requests for a socket. If we have an average 8,000 bid requests per second, this rapidly brings us to 24,000 messages per second to a single process. There is no way the VM can sustain that for long periods of times. If we instead choose to divide the requests between three load-balancers, then we have a possible peak of 8,000 messages per second to a single process. That's still a lot (even too much), but it's far nicer than the multiplicative result we get with a single load-balancer for many bidders.
The Error L(a|og)ger
At some point in time this winter, we started having the following graphs showing up, with alarms flowing through our e-mail boxes in the middle of the night:
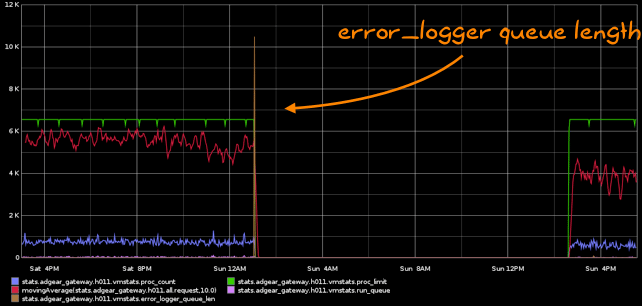
Plenty of people have seen this before. There is some chain of errors that start happening, and all of a sudden, the error_logger queue is growing out of hand and the VM dies by going out of memory (OOM). This is actually worse than having no logging at all. It crashes so fast we can't know what the error is and the VM cannot recover.
If you had that problem before, you picked one of two options: you turned logging off or used an alternative logging library. We picked the latter and chose to use Andrew Thompson's lager. And very quickly, the results were visible:
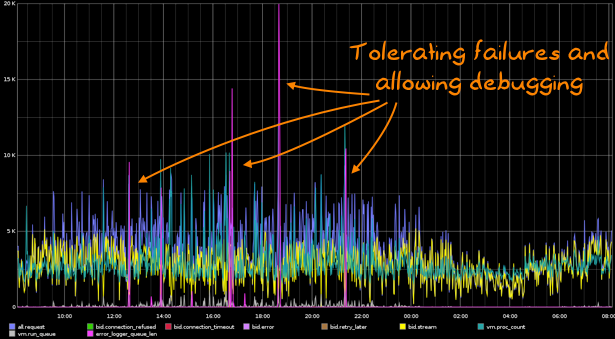
This solved the problem right away. Although the logs were very large and cycling so fast we were often missing the original source of the issue, the VM could stand its ground and tolerate all kinds of crashes. It turned out that our problem was that one exchange would often send us misshaped packets with erroneous content-length values. This crashed the outdated version of Cowboy we were using; upgrading allowed us to deal with it correctly. Since then, the VM managed to become fairly stable.

Scaling the operation
One thing we did was writing our own bidder, running locally on the gateway nodes. There isn't too much to say about it as for now it's fairly basic. One thing it did, though, was force us to think about configuration a whole lot more. One of the common problems of RTB configuration is that you want it to be as static as possible in order to optimize it, but to be able to change it as fast as possible in order to correct error (someone saying they want to spend millions instead of thousands). The solution we picked was to have one central point of origin for all config data:
{kind=link}
The pink node in the center is the controller. It takes two roles. One as a web service to external bidders who want more information on some bids, and one as an application that pushes flat BERT files on all of the gateway nodes. The BERT files are then loaded up by bertconf and transformed into local ETS tables. Bertconf then looks at the files for changes at a regular interval, and when it detects anything new, it reloads the new file, makes a new table, and swaps it with the existing one using some trickery to insure there is never any request failing (hint: it works a bit like module versioning in the VM with purges).
This option is somewhat safe because it only depends on the central node to push updates, not to read them. As long as there is a local bert file, we can reload it in memory even after crashes. It's also stupidly easy to override a file on a single node or to manually replace the central service if we need to. Another nice aspect is that because we will read the configuration on pretty much every bid request ever, it's great to be able to avoid going outside of the VM to fetch the values we need. If we can stay local, we will. FOR SPEED! Maybe in a year or so we will have so much configuration we won't be able to hold it all in memory, but in the meantime, bertconf appears to be a good option.
Pedal to the Metal

The config flexible and fast, a basic bidder in place, HTTP libraries stable, and exchanges integrated. All we needed to do is open the gates to the system. And then it hit us. Cassandra suffered.
The problems with it were that cassanderl's pooling system wasn't especially robust, and that Cassandra itself had to do a lot of requests which would sometimes be really long (insert comment about Java GC):
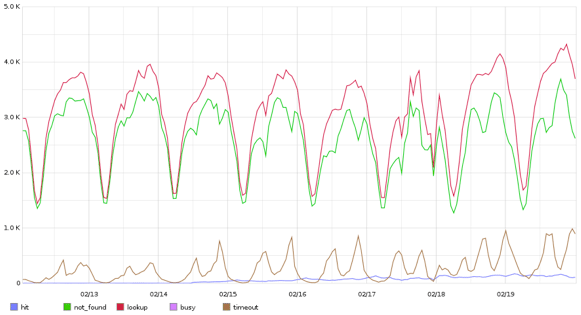
The problem here is the brown line, the timeouts. this shows that out of 4,000 requests per second, we could reach up to 25% of them timing out. This is pretty bad. Here's an explanation why that's possible.
Queues Suck (for this)
Most pool systems are based on a queue (usually the message queue) of different requests to execute. Things usually work fine if we are able to process data as fast, or faster than it enters the queue:

However, a problem happens when elements join the queue faster than they leave it:

When this happens, requests further down the queue are bound to have less and less time to be processed off the initial 35 milliseconds. In fact, at some point in time, all requests are going to be stale until we throw them all away, and start the cycle over and over again. This is actually what happens in production for us, given that we are always getting thousands of requests in the queue each second, but might have only 200 connections open to a database. We are in constant overload, and we're going to see bumps all the time where we sometimes serve one request with a lot of time left, and then serve many with only crumbs of their initial allowed time left, most of it spent idling for no good reason.
Stacks Are Nice (for this)
Let's imagine that instead of using a queue, we're using a stack as a mailbox. Then even in situations of overload, we're always going to pick the newest element on top of the stack:

The stack model works fairly well in cases where you have bursts of overload and can then catch up later. When you're done with all the fresh queries, you'll hit a batch of stale ones that you can try to quickly discard and go through, saying "I won't bid on that" to the exchange. This is awesome, right? It isn't. Remember, for our gateway, we're in a situation of constant overload. This mean we likely will never hit a stale item in the first place, and so we would need to use some kind of bucket-based approach or have a garbage collector specialized enough to throw away old requests. This isn't good enough.
Nothing is Better
By 'nothing is better', I mean nothing as in 'no stack', or rather, a stack with an upper limit of one element. Here's the idea. Whenever we're handling one element, we won't be accepting anything else. We don't care about serving an item that has to wait because it means we're going to have less time to do it. And because we're always in overload, we can pretty much guarantee that there will be an element to take the place of the one that just finished right away. There's just so much stuff coming in there is no reason for any queue to build up. All we have to do is say to the requests that can't make it to the 1-element-stack "sorry guy, I guess you won't bid on this one".

That's the important idea. We don't actually have to serve all the requests. Those that don't fit right away, we can just answer back with "sorry I'm not gonna bid" to the exchange and wait for more. We will in fact get much more throughput that way than if we were to try to do a half-assed job at answering queries with nearly no time left. We're just doing the equivalent of a preemptive time out. We'll get better throughput, yes, but we're also guaranteeing that we will also maximize the time of all the requests making it through to the bidders. That's useful.
Dispcount
Dispcount is a library we built at BLOOM to harness the idea above. We prefer to answer with a no-bid response than not responding on time, or even to losing time on a request given new ones will take their place instantly. It actually works without using message passing as a way to bypass the mailbox (a queue, oh no!), and we've integrated it into cassanderl.
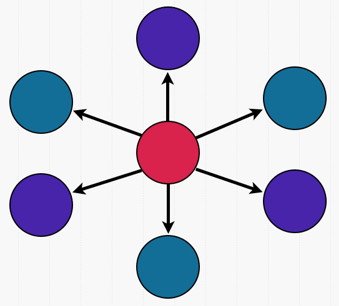
Dispcount pushes the idea a bit further by trying to avoid all central points of communication — a play on single points of failure, where we want to avoid having everyone wanting the same chunk of data. It starts N resource watchers, and works on the idea of "you know what you have to do". That is to say that any request done doesn't have to wait on some external information to know which resource watcher to contact. It just knows. In practice, we do this by using some hash of unique data (the pid and a timestamp) and only then it uses a lookup table:
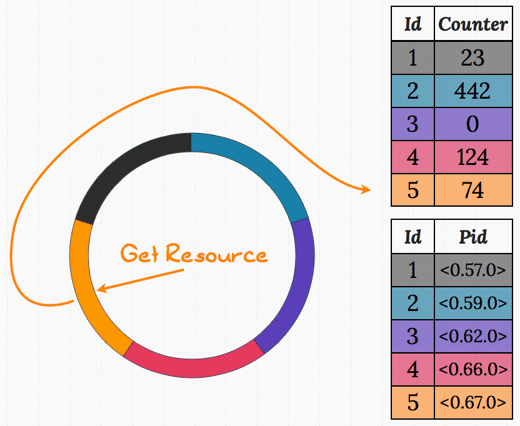
In the diagram above, we have 5 watchers (teal, purple, pink, orange, and black). The request gets hashed to the value 5 (orange) and uses ets:update_counter/3 to increment the value atomically. If the value returned after the incrementation is 1, then you know you have access to the resource. If it's anything else, you don't. In this case we don't, because the value returned is going to be 75.

In the image above, some request got hashed to the purple color. The counter update returned the value 1, and so that request has gained the right to the table containing pids. The resource can now be requested from that pid with a single message.
There are a few things to explain here. First of all, the distribution of requests is non-deterministic. It's entirely possible that a system under no load and with a thousand resources available gets a few busy messages with only 3 requests. However, under heavy load (which is our case, all the time), statistics pretty much guarantee us that we're going to get full usage of all the resources. Whenever the resource gets checked back in, the counter is reset to 0 and a new request can obtain it.
Secondly, I feel I should explain why I use two ETS tables and why I use counters like that. The reason is actually very simple. ETS tables, when switching between read and write modes, are relatively slow. On my own laptop, I benched about 500 operations per second on a table when mixing reads and writes. When staying only in read xor write mode, I couldn't hit a limit there first — memory or the schedulers working hard on all the processes would be a problem before that. By splitting the table in two, one in read mode and one in write mode, I avoid the switching. By using ets:update_counter/3, I can actually both read and write the data as a single write operation, tricking the VM into giving me more bang for my buck.
I would also not recommend the use of dispcount to anyone who is not allowed to do things like avoiding to process some requests or actually isn't in a very frequent situation of overload. The repository explains the conditions and assumptions that were made when designing dispcount in detail.
So what were the results?
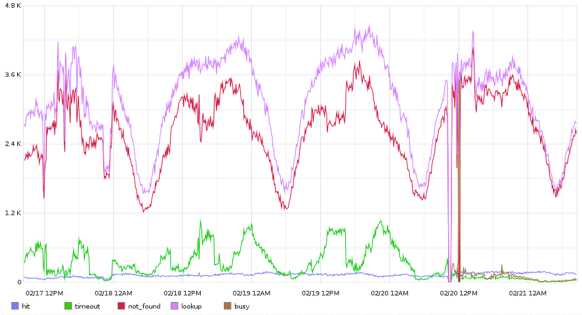
This shows the impact of dispcount in production right after a (somewhat painful) first deployment. What's interesting is to see all the timeouts (green bumps) getting squashed after the deployment. They are not replaced; in fact, you can see that only a minimal amount of requests need to be discarded (the brown line). By making the initially non-intuitive call of dropping a few requests, we in fact ended up serving a lot more of them. This is due mainly to the fact we never accumulate requests, and thus do not end up busting all their timers in a losing race. Dropping requests in fact lets us serve a lot more!
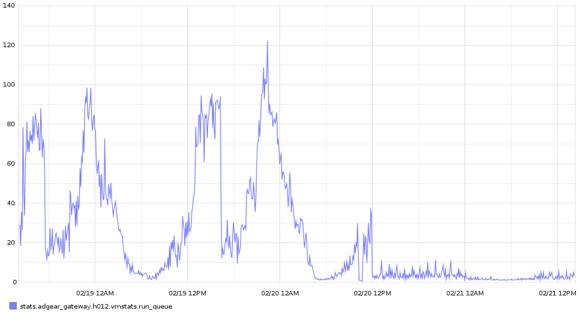
This graph shows the run queue during that same period of time. Having all these requests building up in mailboxes had the Erlang VM working very hard to try and go through all of them, including garbage collection. Using dispcount removed all of these issues pretty much instantly.
Further Optimizations
One thing we've spent a lot of time on is trying to reduce all the work done in encoding and decoding bid requests and responses. All the JSON, protobuffs, and even just HTTP requests are making our gateway dangerously close to being a CPU-bound application.
One thing we tried was changing all the encoding of outgoing JSON from NIF libraries like ejson to using iolists. Our data shows very little variation, and in theory, it was promising. Our first benchmarks instead revealed that there was very little gain to be made, maybe 5-10% at best. The thing, though, is that these benchmarks were sequential — encoding random copies of our JSON structures in a tight loop. When we started measuring things by using as little as a hundred and fifty concurrent processes, suddenly the changes were much more noticeable. Iolists would now be two to three times faster than ejson. What we're suspecting is that some NIFs might tend to behave differently in parallel than concurrent setups. Sequential benchmarks are not always representative of reality, especially when the reality isn't purely sequential.
We've in fact started what could be seen as a witch hunt to all non-essential NIFs in our system. They caused us other problems, such as crashing the VM when doing cowboy-style hot-code loading (we actually do not need relups as they're slower and our requests are short-lived to a point it's safer to hot-reload without protection than locking everything). We currently just skip reloading them, but doing away with them wouldn't sadden us. Note that other systems with constraints different than ours might embrace NIFs. Different requirements yield different optimal solutions.
Finally, what we want to keep on doing is decentralizing more. Single points of failures and single points of communications are all annoying things that limit how much we can push our gateways.
Thank you for reading this talk. Any questions?