The Hitchhiker's Guide to the Unexpected

This is a transcript of a talk given at ElixirDaze and CodeBEAMSF conferences in March of 2018, dealing with supervision trees and with the unexpected.
Among other things, I'm a systems architect, which means that my job is mostly coming up with broad plans, and taking the merit if they go well and otherwise blaming the developers if it they go wrong. More seriously, a part of my job is helping make abstract plans about systems, in such a way that they are understandable, leave room for developers to make decisions locally about what they mean, but while structuring things in such a way that the biggest minefields one might encounter when the rubber hits the road are taken care of.
This is kind of critical at Genetec because we’re designing security systems that are used in supermarkets, coffee shops, train stations, airports, or even city-wide systems. There’s something quite interesting about designing a system where if there’s any significant failure, the military—with dudes carrying submachine guns—has to be called as a back up for what you do (to be fair, I'm not the one who designed these, those are stories I heard!) The systems are often deployed at customer sites, with no direct management access by its developers. So the challenge is in coming up with solutions that require little to no active maintenance—even though they must be maintainable—must suffer no or little downtime, and must make the right decisions when everything goes bad and the system is fully isolated for hours.
Few of these plans survive the whiteboard, and most of them have to be living documents adapted to whatever developers encounter as they work. I think this is because of one simple problem underneath it all: we don’t know everything. In fact, we don’t know much at all.

So this is me at work. Trying to help along the way. One thing I've noticed happening over and over again though is that the vocabulary that OTP gives us as a framework really helps with all of that stuff. I barely remember how to build a system without it, and no matter what I design now, the OTP approach seeps into it. And what happens, no matter if the discussion is about Erlang systems or any other language, is that I keep coming back to these principles and using them.
So today that’s a bit of what I want to talk about. How can you design your system for actual fault tolerance, to deal with the unexpected, to deal with what we don’t know can bite us in the ass, specifically in the context of Erlang and Elixir systems.
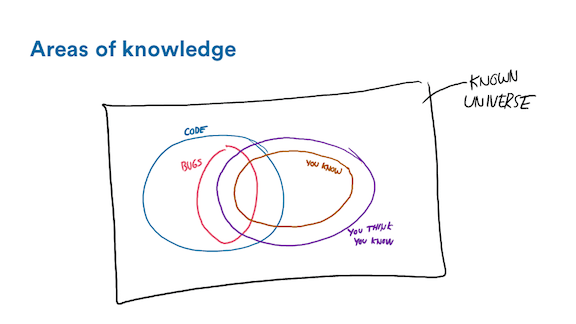
So first of all, I think it might be useful to try and define where the bugs in our systems can come from.
There's this brown-orange area right here: those are the things we know. We have experience, we have measured them, we know them to be facts. It's a smallish circle and it only partially overlaps the code we have in our systems. Most of the code we have to answer for, as people writing software, is code we know almost nothing about. The stuff we've written is dwarfed by the code from the libraries we use, the virtual machine, our operating systems, and if we're in the cloud, then there's hypervisors and all the other services we depend on.
Chances are this area is not too significant. However the good thing is whenever we have a bug in our system that's in that brown-orange circle, we can deal with it pretty well. It's easy. We know the code, we know the problem domain, we have an idea of what to do to fix things. Chances are the bug is in a place we knew we'd find it: maybe around a TODO we left behind with missing error handling, or maybe it was found in development already and we just decided to ship the code anyway because of time or budget pressures. In any case, those are simple enough.
The purple area, now that one's interesting. Those are the things we think we know. We've never really double-checked these. We just extrapolate and guess about how the world works based on things we do know. We look at a part of a system, make a guess about how it works and go "there's no other way this could work, it wouldn't make sense." But it's never exactly how we think it is, and the world doesn't make much sense and so we're wrong.
The bugs we cause with this kind of issues are all over the place. If it happens at the top of the Jenga towers that are the systems we build—maybe it's something like how a file logger deals with overload and how it may truncate some data we didn't expect—it's not too bad. On the other hand, if it's at the bottom of the Jenga tower, then those small wrong assumptions can be very dangerous to the overall stability of the system.
My favorite example there is how the TCP stack tends to behave differently if you're on the loopback interface or the other external ones. On a loopback interface, error detection is mostly instantaneous, and even sending data can detect faults. But on any external interface, basically what you have in the real world, this just doesn't happen. So if you built your entire system with local tests, it's possible that the production one will just be plain broken, and in a rather important way.
But that's alright, because the most annoying section is the one that's in neither circle; the things we don't know. This is a fun category because any example I give automatically leaves that category. The bugs here take you by surprise, with little that can be done about them. A good recent example was the meltdown processor issue. Side channel attacks few people ever considered to be a possibility turned out to put the security model necessary to entire industries at risk. Another example I like is the thundering herd problem.
If you've never heard of the thundering herd, it's what happens whenever you have a large set of clients and far more limited servers. Whenever there's a big failure that causes all clients to disconnect, they may all try to connect back again at the same exact time. Whenever that happens, the impact they have can be such that they kill the remaining servers, and can prevent the system from ever coming back up. If you have never prepared for that, and you're not in control of the clients, you may find yourself in a very tricky situation.
Now the actual solution to a thundering herd is writing clients that do things such as use exponential backoff with a random jitter factor to them whenever they fail to reconnect. This is good if you know it, but if you've never seen it, it's not quite simple.
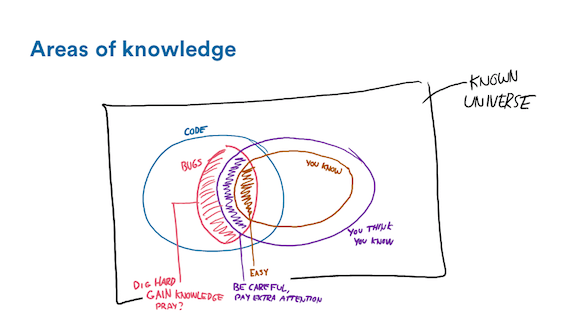
So that's what we get. That orange-brown area is all the easy stuff. It's fine. The purple one, we have to be careful about. We have to pay attention and second-guess ourselves. The red area though, that one is a difficult one. We can dig hard, try to gain more knowledge from other people around, and maybe "thoughts and prayers" can do a thing but usually that doesn't seem very effective.

And so the big question worth a lot of money is how can we shift more bugs from the difficult categories into the easier ones. I don't really believe we can get rid of them all, but if more of them are easy to handle then that's probably a significant improvement.

The simple but difficult solution to this is to increase the knowledge of developers. If you know more stuff then you've got to believe there's going to be more bugs that fit the "things you know" category.
The simplest and easiest way to do that is to hire more senior developers. They're going to know more than junior ones, and so the circle of things they know will cover a wider area than other people. The thing with senior developers is that you must resist the temptation of sending them on their own in one corner of the code mines to write up some of the difficult stuff you have to do, all on their own. Then eventually they leave for another place, and the only thing that remains behind is badly documented work that you now have to answer for with no way to maintain or operate it properly.
Instead, what you should aim for is fostering a culture of teaching, mentorship, and of training. The sign of a healthy team is not one where you have to poach senior people, see them leave, and then poach more senior people. A healthy team is one where the input is junior employees and the output is more senior employees. That means that when people grow out of your organization and seek new challenges, you are not left with a bunch of employees you never took the time to train, but with a team that overall could teach things to each other, share knowledge, and ultimately prevent systems from becoming legacy. Because that's what a legacy system is: one that nobody knows how or wants to maintain.
The second way to increase knowledge is to have a more diverse team. If I'm hiring someone who I've been friends with for years, went to the same school I did, or with whom I worked all the same jobs, there's a very good chance that my orange-brown circle of knowledge will overlap that person's orange-brown circle of knowledge in major ways. What this means is that when it comes to general knowledge, we risk having a pretty similar perspective on things, but also share most of our blind spots. If I'm instead looking for people who have a different background than I do, whether in terms of education, professional experience, different hobbies, or a different cultural background, there's a far bigger chance that our respective circles overlap less, and that more bugs can be prevented before we even get to programming.
Think of it as localisation and internationalisation. If you've ever worked with people who speak only one language and have lived in the same town their entire life, there's a good chance they'll vastly underestimate the kind of challenges awaiting them when it comes to making an application available to people in other countries, with different cultures. A lot of very well-known errors or predictable ones when you know different languages will need to be re-discovered by the team when they could have saved themselves the time. Similarly, it's easy for software developers, a population that is generally well-educated and used to reading text, to forget that 15% to 20% of North Americans are considered functionally illiterate and will be unable to extract significant information from a paragraph of text. If your app or system requires significant documentation to be usable, you're losing a huge amount of people before you even got started.
To put the principle another way, if you hire a team of people who love bitcoin, there's a good chance they'll come up with a solution that includes a blockchain, no matter what the problem was. The same is true for distributed systems engineers and various quorum or consensus protocols, and so on.
A higher amount of diversity from that perspective means fewer prospective bugs because as a team, the overall knowledge of the world is likely to be higher than what you'd get within a monoculture. If you do mix that with a good culture of sharing and education, your engineers should be growing not just as technical contributors, but as people as well.
All of that does not necessarily take care of the code aspects of things, though

Loving this image. Pack your laptop, it's going to production!
When it comes to code, one of the most effective approaches you can take is exploratory testing. You take an experienced tester, sit them in front of your program, and let them go hog wild. They go around and play with things, and try to see what the program can or cannot do, and write a report. They're almost guaranteed to come up with a lot of very interesting bugs that nobody would have thought of.
The downside of this approach is that it is generally time consuming, makes it hard to test for some sorts of regressions, and will lack repeatability. It also requires experienced testers, often manual testers, and in many industries, this is a skillset that may be difficult to find. Instead, there are interesting mechanical and automated approaches that can be taken to help find such problems ahead of time.
The first one I'd like to mention is fuzzing. Fuzzing is great. You’re going to take your program, instrument it the right way, and then ask another program to throw as much garbage at it as it can. The objective of fuzzing will be to cover as much branching logic as possible, and to find inputs that can crash your program. One of the most famous examples of that is American Fuzzy Lop, which asks you to instrument your code, give it a way to write input, and then it will try to generate data that will let it cover as many branches of your code as possible. If it needs to generate 15 megabytes of Ws followed by some arbitrary binary data, it may just do so.
The point of a fuzzer like that is to find inputs that crash your program, which would normally be cause for concern, especially in languages without memory safety guarantees. The downside though is that it tries to demonstrate that your program survives on garbage input, but not necessarily that it does the right thing while drowning in said garbage.
For us in the Erlang and Elixir world, Property-based testing is where the fun is at. QuickCheck, PropEr, Triq, StreamData and so on can all be used to explore programs. The strength of the approach here is that rather than just showing whether the program crashes or runs, property-based testing attempts to demonstrate that no matter what kind of garbage you throw at the software, it still does the right thing. It will necessarily search differently and you may tune it to not seek crashes nearly as much, but one thing property-based testing will do is find corner cases you did not know existed.
From that point of view, these frameworks don’t really increase your knowledge of the system, they just do the work for you so that you can still get the benefit of the knowledge without having had to gain it by yourself. At the same time, you do get to learn about how vague requirements can be.

If you don’t know what Property-based testing is, I absolutely have to introduce it. It’s one of the most powerful testing methodologies out there, halfway through fuzzing and model checking.
You can use all the frameworks I mentioned to test basic stuff in terms of data generation: does my login mechanism still work with fancy confusing Unicode usernames? Will it blow up on some log formatting? What if I upload pictures with real weird EXIF data? Will that still work? That's the part where the whole exercise looks a lot like fuzzing, with the caveat that because we use properties, we're not just looking for crashes, but also things like "is the system mangling user-submitted data?" which do denote for proper behaviour instead of just staying alive.
But the real interesting stuff comes from the crossover with model checking, and there, few property-based testing frameworks across all languages do it as well as most of the Erlang ones (Python's Hypothesis is always good; StreamData in Elixir has no support for this, and none is actually planned either although some community members want it) and particularly QuickCheck. Let's check how that works through an example. Let's say I have a service for private image storage.
First you come up with rules about your system, such as “a user who deletes an entry from their account should no longer be able to see this picture”, then say “nobody should see entries that do not belong to them”, and then something like “entries cannot be duplicated within one account”. Just these 3 rules. Well maybe a fourth one like "a user must be logged in to upload an entry."
Then you tell the program how to generate data for users and entries, and then you tell it various things it can do with your program, like how to log in, log out, and then add, view, or remove an entry. Then the framework goes to town on your system. It generates sequences of these operations as a data structure, and then executes them for a near-random walks through your code, all while makes sure that all your rules and invariants remain true.

If it finds a bug where one of the rule is broken, the framework then shrinks the counter-example by dropping steps or pieces of data from it as much as it can while keeping it failing, until it finds one simpler case that is easy to analyze. So maybe there’s a bug in the system where if you add an entry, delete it, then re-add the same one, it refuses to do it because it’s a duplicate. Maybe the bug only happens when the same entry is added and deleted more than 3 times. Or maybe duplicate detection crosses account boundaries. The framework can tell you.
By dropping operations and simplifying the data, all while looking for similar failures, the framework is able to remove most superficial operations and irrelevant complexities in the inputs. In the end, what you should get is a rather minimal sequence of all the operations required to cause a bug, one that is much easier to reason about than the initial one. So if what you initially had was a sequence of 40 operations, maybe after shrinking you're gonna be left with 4 or 5 of them that cause the same bug.
One uniquely interesting thing with this approach is that it looks a lot like automated exploratory testing. When you find something the application does that you did not expect, it may be a clear cut bug, but it’s also very likely that you’ve just hit a grey area in your system where it’s not obvious whether the tests or your expectations need fixing, or whether the system itself needs fixing. You will gain insights about what the system does that may shine a light on emergent behavior nobody had planned for. I have not yet seen many non-formal testing methods able to have such an impact on the systems I work on.
I mean, I believe in the technology so much I’m writing a book about it right now, though we don’t have a cover for it yet so I can't show it on a slide. There's a draft copy at propertesting.com if you're interested.
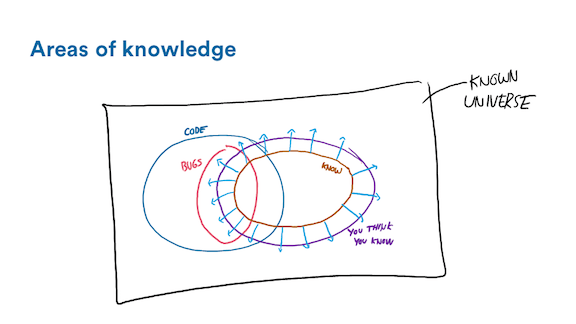
For all of these, the consequence is that you expand the areas of things you and your team know. Both within the system and outside of it. That’s great.
And one funny thing that (you must hope) happens when your team is continuously learning and proving itself wrong is that the gap between the things you know and the things you think you know shrinks. As we bump our heads against the real world, we hopefully start to smell traps and gaps more easily, and become more accurate in all our guesses—or rather, we leave less stuff up for guessing. There’s of course no guarantee in that, and it may just oscillate between both. When you keep proving yourself right, you get to inflate that area of “things you think you know” and then you bump your head again. We all go there.

The next general approach we can take with our systems is to prevent ourselves from getting into areas unknown, or to put safeguards to prevent or reduce the chances we do something odd and unpredictable.
The easiest way to that is to just write less code. The less code there is, the less there is to know. A great system decision is when product folks and engineers can come to an agreement in small changes or ways to do things that result in as much user satisfaction with far less code. Doing that is almost guaranteed to make everything better overall.
Of course that's not always a possibility and we must end up with code in the end. So let's talk about how we can handle that risk factor.
The most powerful tools there are formal methods. Formal specifications like TLA+, exhaustive model checking, automated proofs, and so on. Those try to reason so strictly about things that you’re going to ensure nothing in your system is not understood; everything is proven to work. This tends to work very well, but it’s more difficult and requires more discipline than other ways to go about things.
There’s other ways to decrease the unknown, some that might be less effort-intensive. You can be strict about your assertions, use type signatures and type analysis, write less code, and have more observable software for when problems happen.
For us in the Erlang and Elixir world, the following are all worthwhile:
- Use Dialyzer to prevent unexpected type errors and invalid states
- Use linters or code formatters; code that is more uniform and easy to understand prevents issues
- Very importantly, Let it crash. Don’t try to massage unusable data into acceptable data. The only results of trying to plow through errors is that you end up in a situation that neither the user nor the system expected, and now you're stuck with it. Instead, just bail out as fast as you can so that unknown conditions in one component do not bubble up into unknown conditions system-wide. This helps prevent various classes of emergent behaviour, and that's really worthwhile.
- If you can afford it, use formal tools
One last thing I want to point out is that if things do go wrong, they won’t necessarily go wrong in the places you planned. If you had planned for them to go wrong, chances are you'd already have tests and logging around there. But the big errors that are costly are those that surprise us. This means that you are very likely to have no logging, few metrics, and near zero insights around these at the time they happen. You'll have to figure it out. If you have customers who control their own release cycle, that means that debugging one thing can take multiple months.
Observability practices can turn this in a few hours of poking around instead. And as it turns out, the Erlang VM is built for that, from the ground up.
So learn how to introspect the VM, how to use tracing, and how to dig for the information you need even when it’s not in logs or in metrics you have. I’ve written Erlang in Anger to help you there. We’ve been given a VM and languages that are observable so that even if our code is obtuse and hard to look into, you can still get the data you need out of it. That’s a blessing few other languages have. Embrace it fully. Train engineers on your team to know how to use it.

Okay so for the next step I picked this painting. I absolutely love it, and it perfectly represents the feeling of irrelevance I want to talk about here.
Making the stuff you don't know irrelevant is a bit of a shady trick, but you all know it in some way. There are some classes of bugs that you can just all group together and handle in the same way. When you do so, no matter what the bug is, it’s covered.
The most intuitive one is the one that has to do with redundancy. If you have multiple nodes that can handle the same traffic, then at any time one of them fails, for any reason whatsoever (be it for hardware faults, power loss, running out of disk space or memory, and so on), all the faults can be covered by redirecting traffic around. So whenever you can afford redundancy and can handle an unknown condition by crashing, you've just automated recovery even if you don't really know the cause of the issue. There will be some pathological cases, but you'll likely have prevented more than you created.
There's plenty other architectural patterns that are worthwhile for that, and they can be fairly easy to find in general literature. Instead here I want to focus in a thing fairly unique to Erlang and Elixir: the supervision tree. The supervision trees the OTP framework gives us let us create absolutely flexible structures to care for and handle errors without knowing what they are.
So here I’m going to really get into some supervision patterns to make sure things work well!
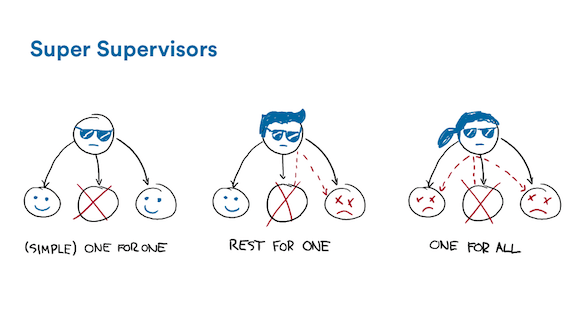
First, if you're not too familiar with supervisors, there's 3 types of them.
The first one is the "one for one" supervisor. It's pretty basic, and what it does is just restart a failed child, back to a known stable state.
The second type is the "rest for one" approach. This approach denotes a linear dependency between children, such that if I have children A, B, and C, then B must depend on A to work, and C depends on both B and A (even if only transitively through B) to do its job. A, for its own, depends on none of its sibling to be successful.
The "one for all" strategy will kill all children if any of them fails. This is usually a thing you'll need if all of this supervisor's children depend on each other to work. Say for example you're doing a two-phase commit. Any worker disappearing and coming back may be really difficult to handle properly. Using a one for all approach will instead just ask you to kill all workers and try over again from a clean slate, something much simpler to get right that handling all the possible interleaving of a complex multi-process protocol when trying to repair things.
So those are simple strategies, but we just need a little bit more to make them really useful.
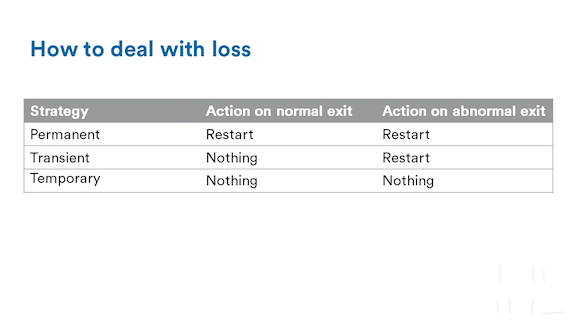
The question there is how to handle a process dying on its own, not just with regards to its siblings. There's 3 of them. A permanent process will always be restarted no matter what. Think of it as a critical service that must always be there. Then we have the transient processes. Those are processes that will be allowed to shut down and disappear only if they have done their job properly. If they ever die of an unknown reason (think of a Unix process dying with a non-0 return value), then their execution will be retried.
Finally, there's the temporary processes, which never get restarted. Those can be a bit odd, but they have their use cases. For example, just tracking processes for the sake of it, but there's a more interesting one I'll show soon.

So here to make everything easy to understand, I'll guide you through the same kind of exercise I do in my own projects, but also with every team I work with when it comes to building a system. We do this exercise before any code is written at all, and it really helps deal with everything.
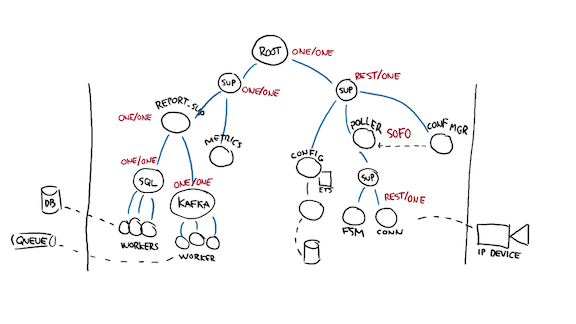
The first thing we'll have to keep in mind for this kind of whiteboard session is that supervisors always start their children in order, depth-first, from left to right. So let's see how one of these design sessions goes.
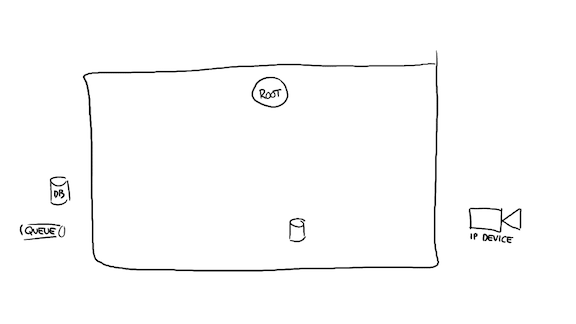
Let's start by identifying our resources. We have an empty system, with some resources on the left: a database and a queue. There's an invisible network up until the boundary of our system. We then have a bit of local storage on the node itself, as represented by the small cylinder on there. On the other side of the network, to the right, we have an IP device.
This device can be anything: a camera, an elevator, a web server handling HTTP requests (maybe we're a proxy then), any IoT device, or possibly a bunch of cellphones. It doesn't really matter what lives there. The role of our box is to take the data on the left, and operate on it (if it's configuration data, for example) or possibly bring it to the right, or to gather data on the right, and bring it to the left.
That's gonna cover an incredible majority of networked middleman applications, something a large amount of Elixir or Erlang teams aim to develop.
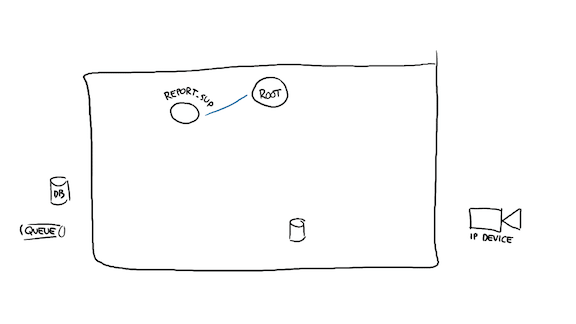
So the first thing I'll start with is going with the left. Since it probably contains configuration data I'll need for the right-side of things, to know where to connect to or who is allowed to connect to me, I'm going to need that side first.
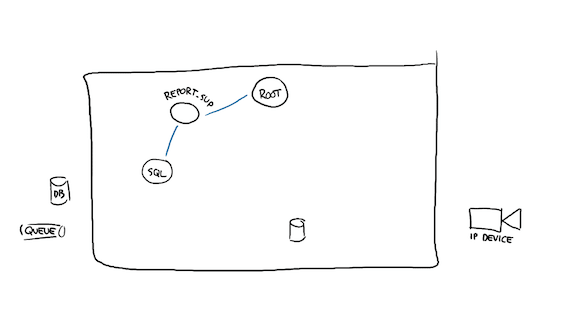
Then I'll probably need to connect to either of my storage endpoints, here it would be Postgres maybe. So I start a supervisor for a worker pool, and then start the pool itself:
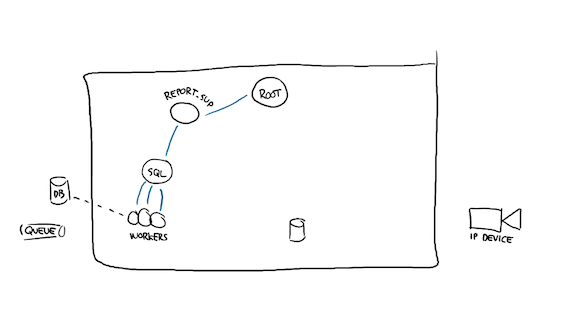
The workers may try to establish a DB connection, and then the system can get back to starting its other children.
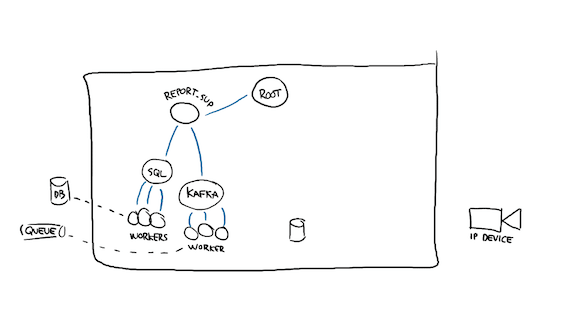
The queue side of things likely works the same; I boot a pool of Kafka consumers and publishers and I'm ready to go back up. What can I need then?
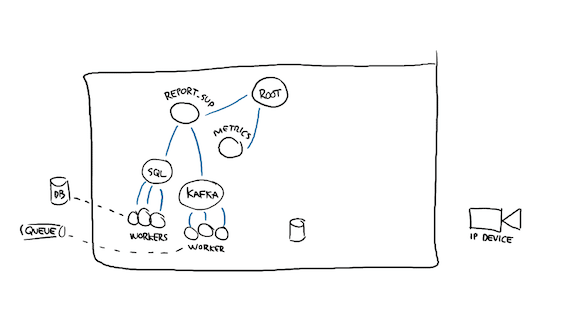
Well I'll probably want metrics. Even if you want observability, there's always a few good metrics you want. Anything that can be a proxy for problem detection, stuff like latency, load, number of requests handled, and so on.
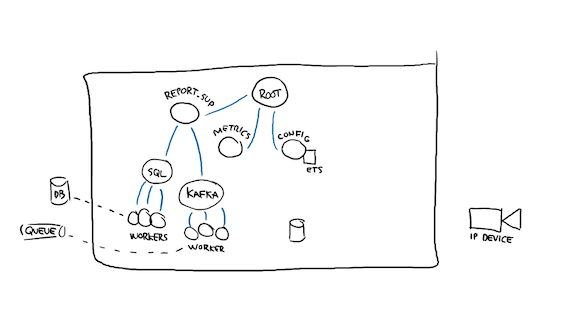
The next bit, since I'm working with a network and must expect a network to fail, will be to probably cache configuration data in memory, to save me some costly roundtrips on reading it.
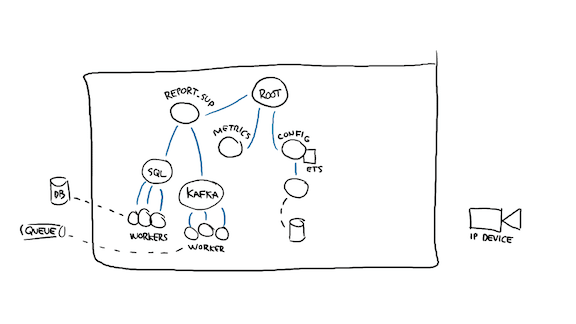
In fact, I might want to store that configuration to disk as well, so that if I crash and come back up to a network that's down, I can come back up. You may not actually want that, depending on the nature of your app, but if I'm dealing with edge devices and I have to report their state upstream, an outdated piece of config may be better than not running the system at all.

Then I can start looking at polling or communicating with the right side. I'm going to start a supervisor that will have many children. Let's see how any single one of them may be implemented.
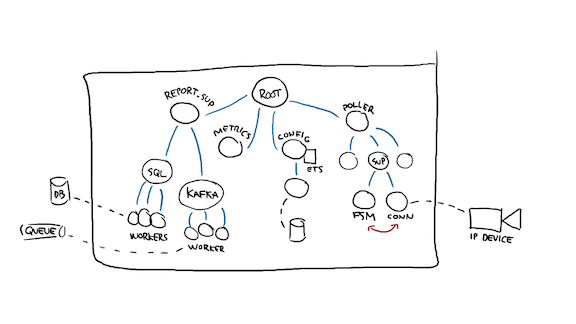
I probably have a middleman supervisor to take care of the two stateful parts of polling: a state machine tracking the IP device's state, and a process holding connection-specific data. These two processes can gather and relay the device's state and bring it to one of the storage workers so that the values can be reported. They can also publish metrics, since the worker for that is already up by virtue of the structure of a supervision tree.
So with all this said and done, we've described all the implicit dependencies between our system components, specified how the system should boot, but also how the system should shutdown—just reverse the order while asking for processes to stop.
That gives us a pretty good idea of how the system works.

Unfortunately, how a system works is the easy stuff. What's interesting is asking how do you want the system to fail, or more optimistically, how do you want it to work when everything around it is failing.
There's one very easy way to handle that stuff, and it's to kill everything with our mind.
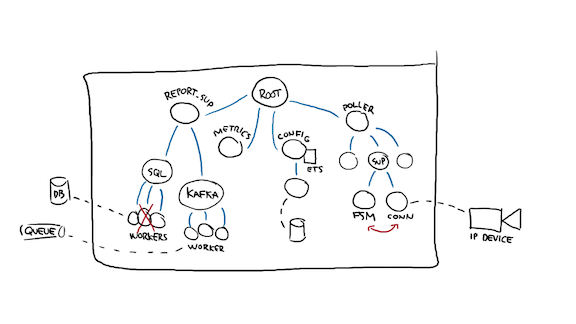
Okay so let me explain that bit. This is what I do with all the teams I work with. I pick a random worker, here, a SQL db worker, and I ask "what should happen if that process dies? Should its siblings die or be kept alive?"
The answer to that is usually "oh no, I don't want all the DB workers to die if only one of them fails", and so we take the parent supervisor, and mark it as "one for one".
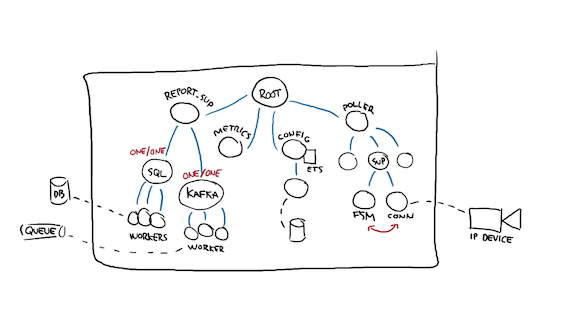
The same process for the Kafka workers can be repeated and likely gives the same results.
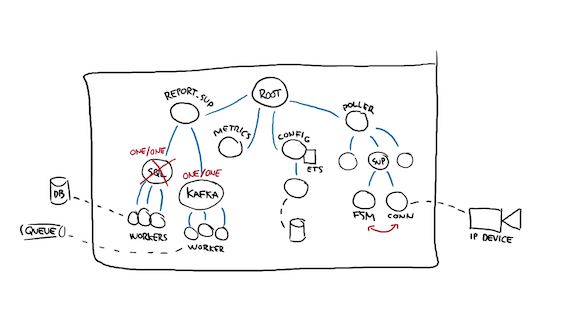
Then I go and ask the same question about these processes' supervisors. If the DB went down too hard and too often, it's possible all of its workers died. When te SQL supervisor dies, should the Kafka subtree die as well?
The answer there is probably "no", so these subtrees' parent is also marked as "one for one"
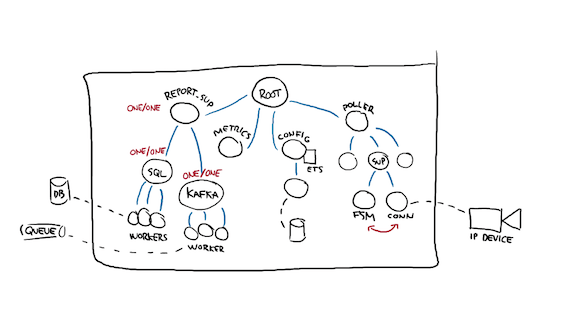
Then I repeat the same kind of thing with all the other processes. What happens if the connection to a device dies? Should the FSM die with it? Maybe! If you're working with a web server and there's no state to persist across queries, then maybe it should die with it.
If I'm polling an IoT device, then I probably want to stay alive to report state changes or accumulate them even during a period of downtime.
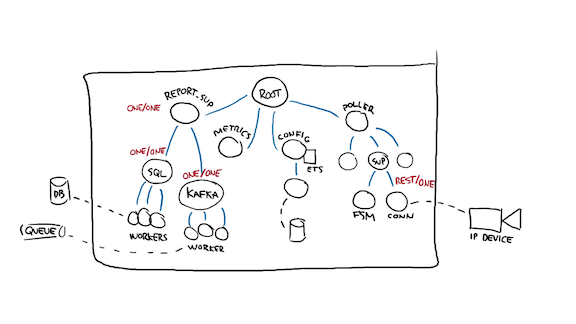
So I can mark that supervisor there as "rest for one", and I can probably take out the link between the two workers as well since the supervision structure now encodes that on its own.
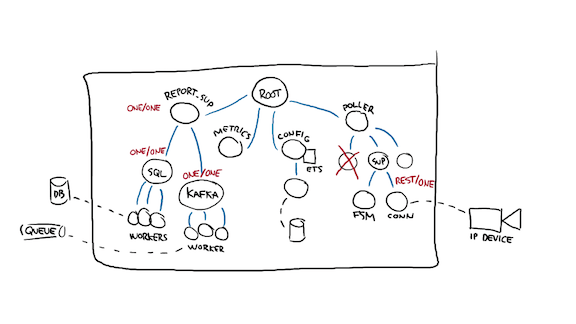
And then you ask the same question. If one of the devices' pollers die, should others do as well? I don't really think so.
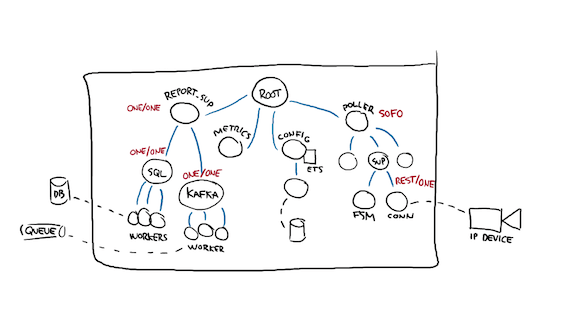
Since I may have any number of devices, maybe hundreds, marking that supervisor as "simple one for one", a highly optimized variant of "one for one" for cases where many processes run the same code with a slightly different configuration, I can get what I want.
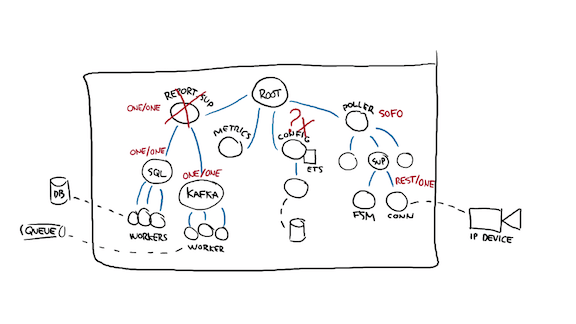
Eventually we may reach a point where there's no obvious answer to dealing with the death of a process, or no way to encode that answer. Here for example I may ask:
- What if all the databases are down? Can I still write and accumulate metrics? Maybe so
- if all the databases are down, should the local cache die with it? probably not, since it's a cache added especially for that purpose
- If the config worker dies, should the poller be able to still work? Probably not
- If the DBs are down but the config is up, can the pollers work? Probably, yeah.
So this gives us one conflict already (one for one relationship between two workers, on the same level as a rest for one relationship!)
The wrong thing to do here is to give up, or write fancy code that handles all these weird corner cases.
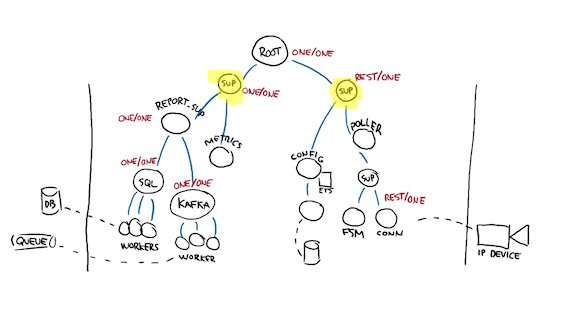
Instead, what I suggest is that we just patch up the supervision tree, even on the whiteboard. This is not necessarily obvious, and it took me years of experience to take a step back, think about the system rather than its components, and figure out that just moving subtrees around was good enough to fix major production incidents for good. So here's what that looks like.
By adding supervision levels, I can declare my new subtree on the left to have its one for one strategy. The metrics and DB pools are independent. I can also declare my relationship between the config and the poller to be a rest for one relationship, allowing me to keep running even if the entire left side of the node vanishes, but not if a local cache is not possible to maintain.
I can make that final relationship between both subtrees official by having my root supervisor use a one for one strategy.
There, just like that, we've figured out how to handle very broad types of outages.
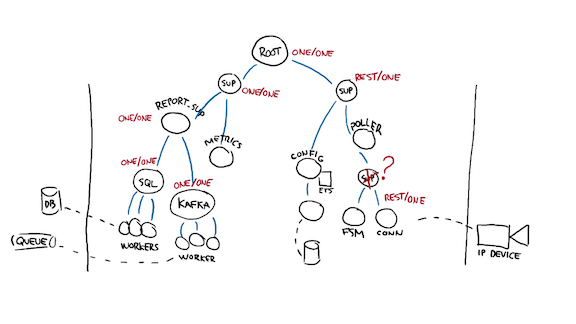
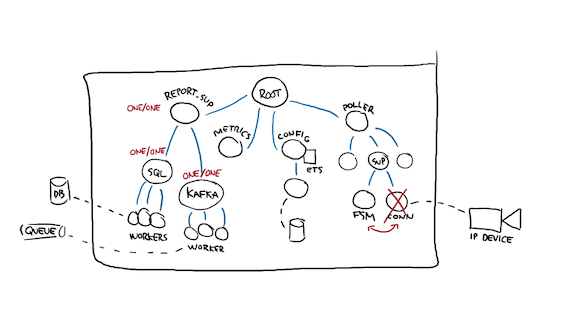
So let's get back to our "kill all the processes" approach. An interesting question to ask is what happens if the IP device I'm interacting with goes bonkers, and throws garbage at me, to the point where the FSM handling it keeps dying?
By default, the worker will be restarted up until it reaches its max capacity, and then the supervisor itself will die. If that happens often enough, the error will bubble up towards the root of the tree and the entire system will shut down. That's bad because now, a single bad device interrupted my talking to all other devices! That's the opposite of what I initially wanted!
That's usually the point where people will go to the mailing list or slack channels and ask for smarter supervisors, with cooldown periods and all kinds of fancy retry logic.
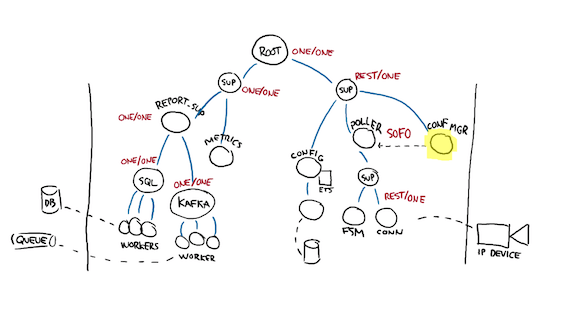
I say no to all of that! I want my supervisors to remain simple and predictable. Smart systems make stupid mistakes, and I want to be able to easily reason about my system. I want to reduce the knowledge required to figure out how things work!
So instead of making all kinds of supervisor variants, here's what I do: I configure the supervisor directly in charge of the FSM and connection to have exactly the error tolerance limits I want them to have. If that threshold is exceeded, I give up on the device.
To do so, I mark the "poller" supervisor as having a temporary setting, the one I mentioned earlier that nobody really knows what it's for when they're beginning. Well that temporary setting is the buffer mechanism by which I go "enough! stop retrying already!"
Then, I add that little highlighted configuration manager. This is me grafting a brain onto my supervisor. What this process will do is go over the supervision tree, possibly compare it to the configuration, and at regular intervals, repair the supervision tree. So it may decide that after 10 seconds, 60 minutes, or a day, the IP device worker can be restarted and retried again.
All the fancy logic I can possibly want is within that worker, and can be tailored to my specific business concerns. I also just happened to have created a central point of interaction with my subtree, so if the Kafka queue wants to talk to the live system, I can create a kind of pub/sub group (with say gproc) and have config workers and/or the config manager listen to it and update their respective parts of the subtree at once. Hell, I can even add additional access points through a web interface and so on, if I really want to.
This also makes the system a lot easier to test and operate, gather metrics for, lets it self-repair things, or allows me to stick giant on/off switches over system changes if I have tricky operations to run.
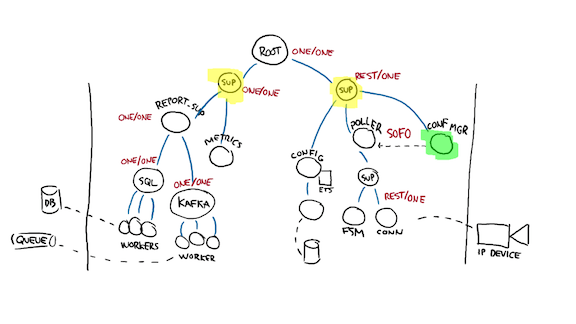
What’s super interesting about this approach to designing systems if that all dependencies, runtime and whatnot are encoded in the supervision tree. They let us create inline circuit breakers such that when something breaks, we know what other kind of work in can halt if it must.
Once you have that stuff in place, writing the system is a charm. If you found out you were wrong about some dependencies or class of bugs, the vocabulary we use is one of "how do we adapt the supervision tree" rather than one of figuring out how to locally handle an error. In some cases the reaction will be to say "you know what, we can’t afford to have an error there, this component is too critical" and so we’ll test the hell out of that one and make sure it’s always doing what it should. That’s maybe possible to do in a small part of your system, it’s just nearly impossible to do it everywhere at once.

At least that's the theory. There's a difference between designing the tree and having it work exactly the way you want on the first try. So here are a few common patterns you may need to implement to make things easier.

I've written an entire blogpost on the topic titled It's about the guarantees, but in a nutshell, what your workers expose as an interface has to represent the failure modes you expect and let the caller know what to expect at the same time.
If you have a local database that should be running before you even start, it's probably fine to have a worker die violently when it cannot access it. If the database is remote however, and you crash on a disconnection, you make your callers die as well. If you think that a remote database may go away with the network from time to time (hint: you should think so), then your callers should deal with the failure. If you crash there, you take away the option of a caller to easily deal with things.
Instead, plan a return value expressing the error condition so you’ll let the client choose what to do: die with you by pattern matching only on success cases, or implement a retry policy to cope with the failure if the data is important.
You have to give enough details to allow decisions you think could be relevant to people. Let those who have the context to make a decision make it.

The one thing you don’t want to happen is blindly retrying the same action over and over again; that’s the definition of insanity. This is particularly critical in cases where you consume data with no way to report back to the client directly, such as when reading from a queue like rabbitmq or Kafka. Some errors are totally natural, such as introducing a new message type, and being mid-deploy and only having half the nodes in the system ready to handle them. You don't want to stall half the cluster in that case.
When you can’t tell a client that something went wrong, you will need to drop messages or requests that never work (don't do this if you must really handle everything, like in a data replication system where dropping unforeseen messages means you fail at your job), and if you do require to process everything, plan for a dead letter queue.
A dead letter queue is your system abdicating and going "I need an adult!" A human being will have to go in, and make a judgment call to fix things. They can drop the message themselves, re-enqueue it, or figure out the system is buggy and hold it in there a bit longer, and maybe rollback the component that introduced it.

Finally, you'll want a mechanism to frame your retries.
One example of this is using incremental backoffs with a jitter factor to prevent using too many resources and thundering herds, as mentioned earlier.
Then you may want to look at circuit breakers, which will let you capture when too many faults happen at once, trip the breaker, and prevent calls you know are very likely to fail from actually doing so. The interesting thing is that you can even include softer metrics, such as "the average request is too slow and so take the foot off the gas pedal" which will let you create systems that slow down and leave some space to other components before the even fail.
That can let you create systems that operate a lot more smoothly, fail for shorter periods of time, and get going back again much more easily as well.

Having a supervision tree is sadly not the same thing as having a well-behaved supervision tree. So how can you know if your tree is right, and that your processes implement the right stuff to work with the structure you want?
There are no bulletproof solutions here.

In fact, the only one I know to work well from experience is to use Chaos Engineering. Chaos engineering is mostly known from Netflix's Chaos Monkey, which would be a piece of software that you would unleash against your production system and let it take down components to see if your system can adapt and cope with failures. Nowadays they do it even on data-center levels. Other practices there can include fault injection, incident simulations, and so on. You aim to define a steady state and then throw failures at it and see if it sticks.
This all can be used in Erlang and Elixir systems, but given we have a supervision tree, there's interesting stuff we can do. In fact, we can use the tree as a model for our steady state. All that's left to do then, is simulate or mock failures, kill random processes (as if they were buggy), and see if the tree behaves as desired.
That's what I did with a little Property-based testing suite. The thing is rather conceptually simple:
- The system is running under active traffic, likely under a load simulator
- The library takes a snapshot of a set of whitelisted OTP applications running in the system
- The library numbers all tree processes, starting depth-first, from right to left (newer processes are likely to be killed first)
- The library picks a random number (and wraps it around if it needs to) and finds the process that matches it—filters and tags can be used to narrow or restrict processes
- The process is killed
- The library navigates the model created off the snapshot and propagates all deaths the way they should be taking place, without actually doing it (no side effects). If two processes live under a one for all supervisor, the second one is expected to die and restart as well, for example. If the restart threshold is hit, then the expectation is that the direct supervisor should also die and possibly be restarted.
- a snapshot of the system is taken after it has had a bit of time to stabilize (and right now this is a bit hackish) and the new supervision tree is compared to the old one
A similar mechanism can be used, but just with fault injection, where a mock, fake process, or circuit breaker is put within the system under test, and on-demand, will return specific error messages (like {error, disconnected}). The supervision trees still get compared there.
The two types of properties we're looking for in the supervision tree comparisons are simple:
- did all the processes that were expected to die actually die
- did any supervisor from within a different supervision subtree die?
In the image above, for example, if the database workers start returning {error, busy}, it's entirely possible for a specific FSM process to die of it. If however too many of them die too often such that their supervisor (or the poller supervisor) dies, then the test suite considers this to be a failure of the supervisor tree implementation: since you're in distinct subtrees, there's either a failure case you should handle and that you do not, or this error condition has to currently be considered catastrophic if you choose to live with it.
That's all it does, and it does find interesting bugs fairly easily, with limited effort from the developer, assuming they understand PropEr as a test framework. The project is still kind of janky and prototype-like, but you can take a look at https://github.com/ferd/sups

So let's say we've got a solid supervision tree, and we fully embraced that mechanism. What can we do with it if we stretch things a bit? Can we do something more than just dealing with Erlang processes?
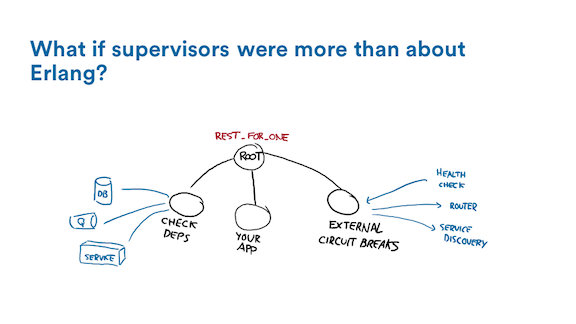
Since supervision trees are all well-structured, we can do interesting stuff. Here on the left side, I'll put all the things I consider to be prerequisites for my system.
Maybe I don't want to boot without an initial network-based configuration, and so I can put, on a worker to the left of the root of my subtree, a check for a disk cache or a network connection being available. Maybe it's to a third party service. In any case, such a check ensures that unless I can satisfy my prerequisites and that all system dependencies are in place, my own system will refuse to boot and start trying to serve traffic.
If any of these goes down and is permanent, it can also shut down my own system to prevent it from doing things it shouldn't. For example, if you're doing transactions or any financial stuff and you lose the ability to publish audit logs, it's very possible you want the entire node to go down; if you can't audit the financial stuff you're doing, you may not want to do it at all. Bam, handled.
On the right of the subtree, I can put the health-related stuff: if I have to register myself to a router, a service discovery mechanism, or respond to healthchecks, I can make specific workers for all of that. The interesting approach of doing so is that if my own system breaks down due to some developer mistake or transient network condition I had not planned for, then these will act as a circuit-breaker. In fact, I can put them anywhere in the supervision tree, not just to the far-right.
The moment a subtree goes bad and I can't do a specific task, then, as encoded in the structure of the program, my system unregisters itself and can stop ingesting traffic until it stabilizes, automatically re-registers itself, and things get back to normal.
All in all, what this lets us do is take the same kind of guarantees about dependencies and partial failures that we get within an Erlang or Elixir system, and encode them into various components to gain some of their insights at a systems level.
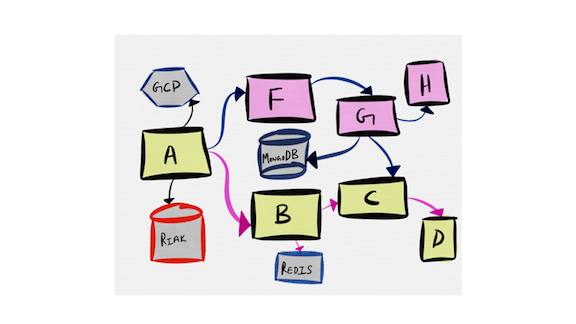
And so we can ask the question of whether this can be applied to other languages? Maybe not. But to other architectures, such as microservices? Yes probably!
Look at the approach that we used with supervisors, and ask yourself whether this could be applied to stream processing systems or microservices, where you can quickly end up with a very messy spiderweb of dependencies.
The system architecture above is clean enough, but you can clearly see linear dependencies between individual components that could easily represented as a supervision tree!
If you go through the same design exercise with microservices, it may become far easier to understand what should impact which components in the system, figure out how to read exceptions and alarms to identify root causes, and overall, make everyone’s life easier. Unfortunately it’s a bit complex to encode a supervisor in a service mechanism, but the pattern can hopefully be replaced through service registries, local circuit breakers, and event feeds. Tools like Kubernetes already have some ways to encode dependencies, but it gets to be a bit harder, for example, to define specific failure rates or ways to break circuits directly from there.

And so that's it in a nutshell. Gain more knowledge, reduce the amount of unknown you can have in a system, and seek broader architectural patterns that can cope with errors rather than just trying to prevent them in the first place. Learn to love your supervision trees, they're pretty unique and pretty powerful.


Thanks!
