Errors are constructed, not discovered
Over a year ago, I left the role of software engineering* behind to become a site reliability engineer* at Honeycomb.io. Since then, I've been writing a bunch of blog posts over there rather than over here, including the following:
- OnCallogy Sessions
- On the brittleness of dashboards
- How we define SRE work
- Data availability isn't observability
There are also a couple of incident reviews, including one on a Kafka migration and another on a spate of scaling-related incidents.
Either way, I only have so much things to rant about to fill in two blogs, so this place here has been a bit calmer. However, I recently gave a talk at IRConf (video).
I am reproducing this talk here because, well, I stand behind the content, but it would also not fit the work blog's format. I'm also taking this opportunity because I don't know how many talks I'll give in the next few years. I've decided to limit how much traveling I do for conferences due to environmental concerns—if you see me at a conference, it either overlapped with other opportunistic trips either for work or vacations, or they were close enough for me to attend them via less polluting means—and so I'd like to still post some of the interesting talks I have when I can.
The Talk
This talk is first of all about the idea that errors are not objective truths. Even if we look at objective facts with a lot of care, errors are arbitrary interpretations that we come up with, constructions that depend on the perspective we have. Think of them the same way constellations in the night sky are made up of real stars, but their shape and meaning are made up based on our point of view and what their shapes remind us of.
The other thing this talk will be about is ideas about what we can do once we accept this idea, to figure out the sort of changes and benefits we can get from our post-incident process when we adjust to it.
I tend to enjoy incidents a lot. Most of the things in this talk aren't original ideas, they're things I've read and learned from smarter, more experienced people, and that I've put back together after digesting them for a long time. In fact, I thought my title for this talk was clever, but as I found out by accident a few days ago, it's an almost pure paraphrasing of a quote in a book I've read over 3 years ago. So I can't properly give attribution for all these ideas because I don't know where they're from anymore, and I'm sorry about that.

This is a quote from "Those found responsible have been sacked": some observations on the usefulness of error" that I'm using because even if errors are arbitrary constructions, they carry meaning, and they are useful to organizations. The paper defines four types I'll be paraphrasing:
- Defense against entanglement: the concept of error or fault is a way for an organization to shield itself from the liabilities of an incident. By putting the fault on a given operator, we avoid having to question the organization's own mechanisms, and safely deflect it away.
- Illusion of control: by focusing on individuals and creating procedures, we can preserve the idea that we can manage the world rather than having to admit that adverse events will happen again. This gives us a sort of comfort.
- Distancing: this is generally about being able to maintain the idea that "this couldn't happen here", either because we are doing things differently or because we are different people with different practices. This also gives us a decent amount of comfort.
- Failed investigation: finally, safety experts seem to see the concept of error, particularly human error, as a marker that the incident investigation has ended too early. There were more interesting things to dig into and that hasn't been done—because the human error itself is worth understanding as an event.
So generally, error is useful as a concept, but as an investigator it is particularly useful as a signal to tell you when things get interesting, not as an explanation on their own.

And so this sort of makes me think about how a lot of incident reviews tend to go on. We use the incident as an opportunity because the disruption is big and large enough to let us think about it all. But the natural framing that easily comes through is to lay blame to the operational area.
Here I don't mean blame as in "people fucked up" nearly as much as "where do we think the organisation needs to improve"—where do we think that as a group we need to improve as a result of this. The incident and the operations are the surface, they often need improvement for sure because it is really tricky work done in special circumstances and it's worth constantly adjusting it, but stopping there is missing on a lot of possible content that could be useful.
People doing the operations are more or less thrown in a context where a lot of big decisions have been made already. Whatever was tested, who was hired, what the budgets are, and all these sorts of pressures are in a large part defined by the rest of the organization, they matter as well. They set the context in which operations take place.
So one question then, is how do we go from that surface-level vision, and start figuring out what happens below that organisational waterline.
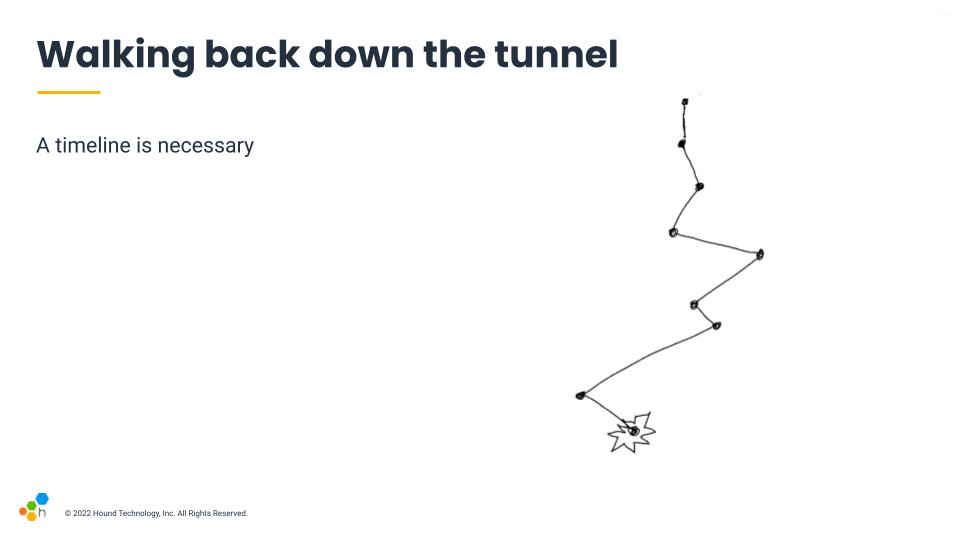
The first step of almost any incident investigation is to start with a timeline. Something that lets us go back from the incident or its resolution, and that we use as breadcrumbs to lead us towards ways to prevent this sort of thing from happening again. So we start at the bottom where things go boom, and walk backwards from there.
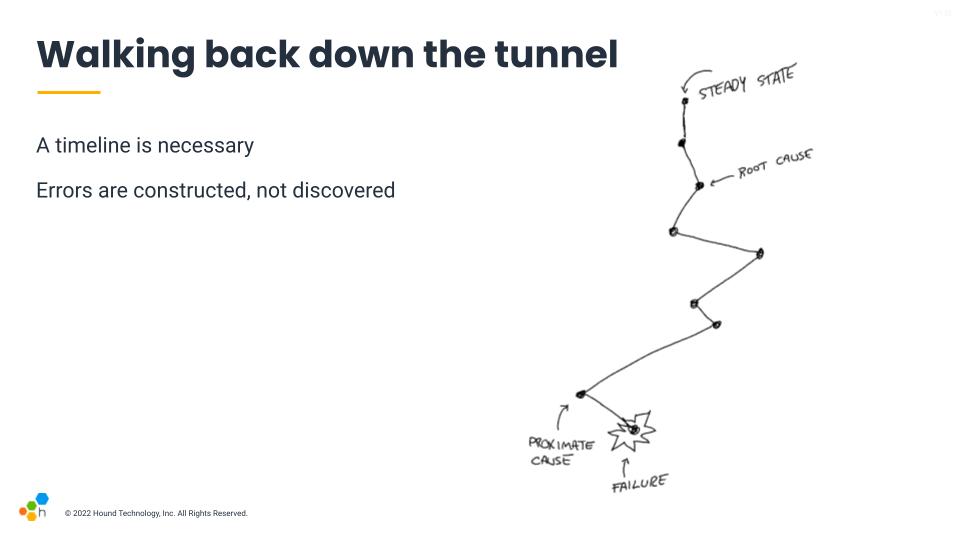
The usual frameworks we're familiar with apply labels to these common patterns. We'll call something a failure or an error. The thing that happened right before it tends to be called a proximate cause, which is frequently used in insurance situations: it's the last event in the whole chain that could have prevented the failure from happening. Then we walk back. Either five times because we're doing the five whys, or until you land at a convenient place. If there is a mechanical or software component you don't like, you're likely to highlight its flaws there. If it's people or teams you don't trust as much, you may find human error there.
Even the concept of steady state is a shaky one. Large systems are always in some weird degraded state. In short, you find what you're looking for. The labels we use, the lens through which we look at the incident, influence the way we build our explanations.
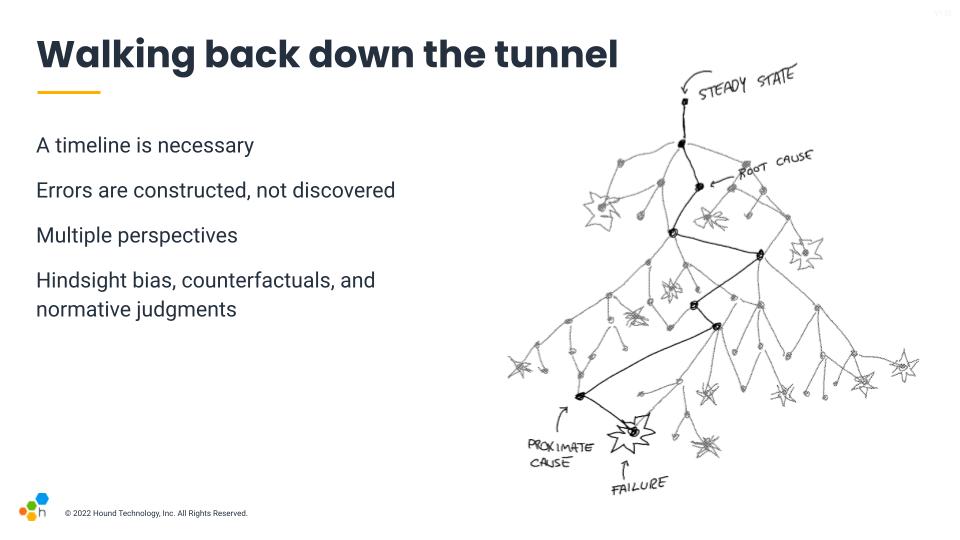
The overall system is not any of the specific lenses, though, it's a whole set of interactions. To get a fuller richer picture, we have to account for what things looked liked at the time, not just our hindsight-fuelled vision when looking behind. There are a lot of things happening concurrently, a lot of decisions made to avoid bad situations that never took place, and some that did.
Hindsight bias is something somewhat similar to outcome bias, which essentially says that because we know there was a failure, every decision we look at that has taken place before the incident will seem to us like it should obviously have appeared as risky and wrong. That's because we know the result, it affects our judgment. But when people were going down that path and deciding what to do, they were trying to do a good job; they were making the best calls they could to the extent of their abilities and the information available at the time.
We can't really avoid hindsight bias, but we can be aware of it. One tip there is to look at what was available at the time, and consider the signals that were available to people. If they made a decision that looks weird, then look for what made it look better than the alternatives back then.
Counterfactuals are another thing to avoid, and they're one of the trickiest ones to eliminate from incident reviews. They essentially are suppositions about things that have never happened and will never happen. Whenever we say "oh, if we had done this at this point in time instead of that, then the incident would have been prevented." They're talking about a fictional universe that never happened, and they're not productive.
I find it useful to always cast these comments into the future: "next time this happens, we should try to try that to prevent an issue." This orients the discussion towards more realistic means: how can we make this option more likely? the bad one less interesting? In many cases, a suggestion will even become useless: by changing something else in the system, a given scenario may no longer be a concern for the future, or it may highlight how a possible fix would in fact create more confusion.
Finally, normative judgments. Those are often close to counterfactuals, but you can spot them because they tend to be about what people should or shouldn't have done, often around procedures or questions of competence. "The engineer should have checked the output more carefully, and they shouldn't have run the command without checking with someone else, as stated in the procedure." Well they did because it arguably looked reasonable at the time!
The risk with a counterfactual judgment is that it assumes that the established procedure is correct and realistically applicable to the situation at hand. It assumes that deviations and adjustments made by the responder are bound to fail even if we'll conveniently ignore all the times they work. We can't properly correct procedures if we think they're already perfect and it's wrong not to obey them, and we can't improve tooling if we believe the problem is always the person holding it wrong.
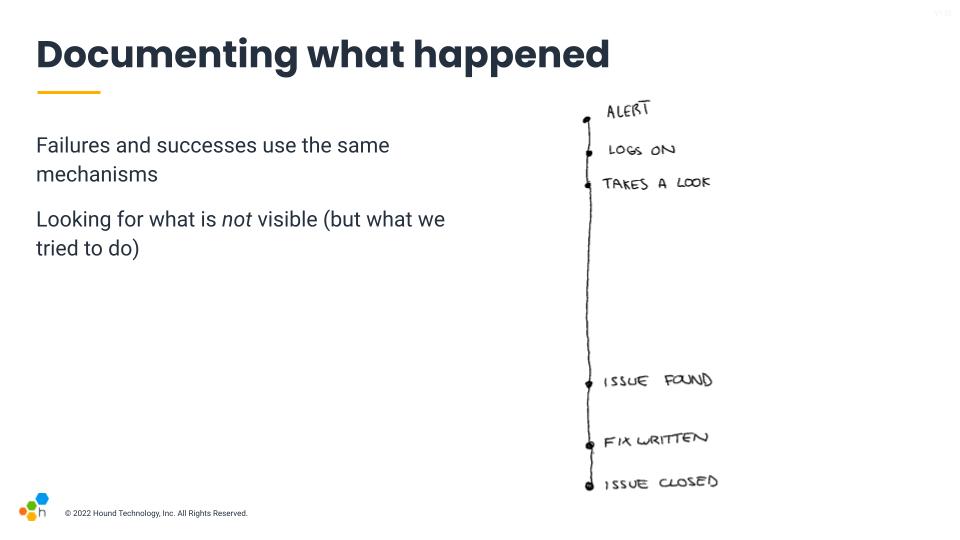
A key factor is to understand that in high pressure incident responses, failure and successes use the same mechanisms. We're often tired, distracted, or possibly thrown in there without adequate preparation. What we do to try and make things go right and often succeed through is also in play when things go wrong.
People look for signals, and have a background and training that influences the tough calls that usually will be shared across situations. We tend to want things to go right. The outcome tends to define whether the decision was good one or not, but the decision-making mechanism is shared both for decisions that go well and those that do not. And so we need to look at how these decisions are made with the best of intentions to have any chance of improving how events unfold the next time.
This leads to the idea you want to look at what's not visible, because they show real work.
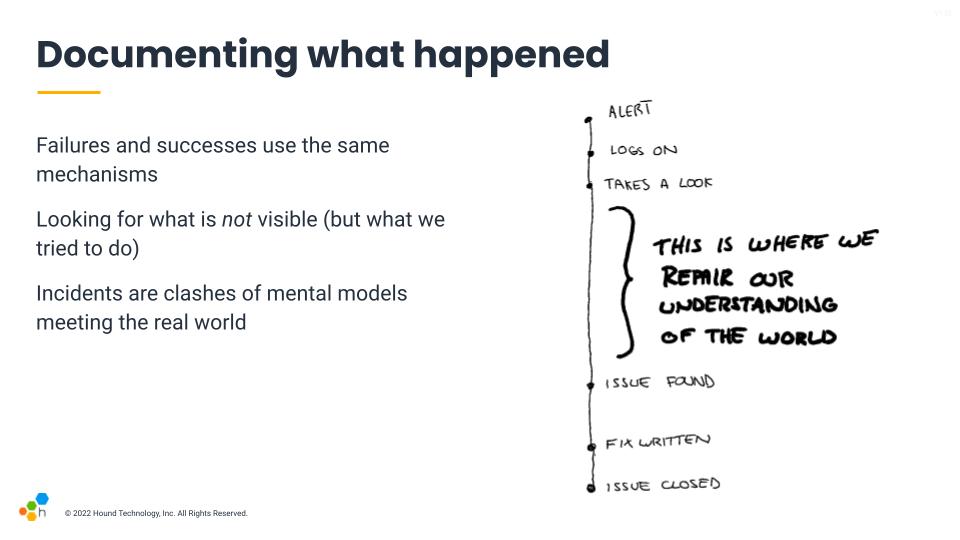
I say this is "real work" because we come in to a task with an understanding of things, a sort of mental model. That mental model is the rolled up experience we have, and lets us frame all the events we encounter, and is the thing we use to predict the consequences of our decisions.
When we are in an incident, there's almost always a surprise in there, which means that the world and our mental model are clashing. This mismatch between our understanding of the world and the real world was already there. That gap between both needs to be closed, and the big holes in an incident's timelines tend to be one of the places where this takes place.
Whenever someone reports "nothing relevant happens here", these are generally the places where active hypothesis generation periods happen, where a lot of the repair and gap bridging is taking place.
This is where the incident can become a very interesting window into the whole organizational iceberg below the water line.
So looking back at the iceberg, looking at how decisions are made in the moment lets you glimpse at the values below the waterline that are in play. What are people looking at, how are they making their decisions. What's their perspective. These are impacted by everything else that happens before.
If you see concurrent outages or multiple systems impacted, digging into which one gets resolved first and why that is is likely to give you insights about what responders feel confident about, the things they believe are more important to the organization and users. They can reflect values and priorities.
If you look at who they ask help from and where they look for information (or avoid looking for it), this will let you know about various dynamics, social and otherwise, that might be going on in your organization. This can be because some people are central points of knowledge, others are jerks, seen as more or less competent, or also be about what people believe the state of documentation is at that point in time.
And this is why changing how we look at and construct errors matters. If we take the straightforward causal approach, we'll tend to only skim the surface. Looking at how people do their jobs and how they make decisions is an effective way to go below that waterline, and have a much broader impact than staying above water.

To take a proper dive, it helps to ask the proper type of questions. As a facilitator, your job is to listen to what people tell you, but there are ways to prompt for more useful information. The Etsy debriefing facilitation guide is a great source, and so is Jeli's Howie guide. The slide contains some of the questions I like to ask most.
There's one story I recall from a previous job where a team had specifically written an incident report on an outage with some service X, and the report had that sort of 30 minutes gap in it and were asking for feedback on it. I instantly asked "so what was going on during this time?" Only for someone on the team to answer "oh, we were looking for the dashboard of service Y". I asked why they had been looking at the dashboard of another service, and he said that the the service's own dashboard isn't trustworthy, and that this one gave a better picture of the health of the service through its effects. And just like that we opened new paths for improvements that were so normal it had become invisible.
Another one also came from a previous job where an engineer kept accidentally deleting production databases and triggering a whole disaster recovery response. They were initially trying to delete a staging database that was dynamically generated for test cases, but kept fat-fingering the removal of production instances in the AWS console. Other engineers were getting mad and felt that person was being incompetent, and were planning to remove all of their AWS console permissions because there also existed an admin tool that did the same thing safely by segmenting environments.
I ended up asking the engineer if there was anything that made them choose the AWS console more than the admin tool given the difference in safety, and they said, quite simply, that the AWS console has an autocomplete and they never remembered the exact table name, so it was just much faster to delete that table often there than the admin. This was an interesting one because instead of blaming the engineer for being incompetent, it opened the door to questioning the gap in tooling rather than adding more blockers and procedures.
In both of these stories, a focus on how people were making their decisions and their direct work experience managed to highlight alternative views that wouldn't have come up otherwise. They can generate new, different insights and action items.

And this is the sort of map that, when I have time for it, I tried to generate at Honeycomb. It's non-linear, and the main objective is to help show different patterns about the response. Rather than building a map by categorizing events within a structure, the idea is to lay the events around to see what sort of structure pops up. And then we can walk through the timeline and ask what we were thinking, feeling, or seeing.
The objective is to highlight challenging bits and look at the way we work in a new light. Are there things we trust, distrust? Procedures that don't work well, bits where we feel lost? Focusing on these can improve response in the future.
This idea of focusing on generating rather than categorizing is intended to take an approach that is closer to Qualitative science than Quantitative research.

The way we structure our reviews will have a large impact on how we construct errors. I tend to favour a qualitative approach to a quantitative one.
A quantitative approach will often look at ways to aggregate data, and create ways to compare one incident to the next. They'll measure things such as the Mean Time To Recovery (MTTR), the impact, the severity, and will look to assign costs and various classifications. This approach will be good to highlight trends and patterns across events, but as far as I can tell, they won't necessarily provide a solid path for practical improvements for any of the issues found.
The qualitative approach by comparison aims to do a deep dive to provide more complete understanding. It tends to be more observational and generative. Instead of cutting up the incidents and classifying its various parts, we look at what was challenging, what are the things people felt were significant during the incident, and all sorts of messy details. These will highlight tricky dynamics, both for high-pace outages and wider organizational practices, and are generally behind the insights that help change things effectively.

To put this difference in context, I have an example from a prior jobs, where one of my first mandates was to try and help with their reliability story. We went over 30 or so incident reports that had been written over the last year, and a pattern that quickly came up was how many reports mentioned "lack of tests" (or lack of good tests) as causes, and had "adding tests" in action items.
By looking at the overall list, our initial diagnosis was that testing practices were challenging. We thought of improving the ergonomics around tests (making them faster) and to also provide training in better ways to test. But then we had another incident where the review reported tests as an issue, so I decided to jump in.
I reached out to the engineers in question and asked about what made them feel like they had enough tests. I said that we often write tests up until the point we feel they're not adding much anymore, and that I was wondering what they were looking at, what made them feel like they had reached the points where they had enough tests. They just told me directly that they knew they didn't have enough tests. In fact, they knew that the code was buggy. But they felt in general that it was safer to be on-time with a broken project than late with a working one. They were afraid that being late would put them in trouble and have someone yell at them for not doing a good job.
And so that revealed a much larger pattern within the organization and its culture. When I went up to upper management, they absolutely believed that engineers were empowered and should feel safe pressing a big red button that stopped feature work if they thought their code wasn't ready. The engineers on that team felt that while this is what they were being told, in practice they'd still get in trouble.
There's no amount of test training that would fix this sort of issue. The engineers knew they didn't have enough tests and they were making that tradeoff willingly.

So to conclude on this, the focus should be on understanding the mess:
- go for a deeper understanding of specific incidents where you feel something intriguing or interesting happened. Aggregates of all incidents tend to hide messy details, so if you have a bunch of reviews to do, it's probably better to be thorough on one interesting one than being shallow on many of them
- Mental models are how problem solving tends to be done; we understand and predict things based on them. Incidents are amazing opportunities to correct and compare and contrast mental models to make them more accurate or more easy to contextualize
- seek an understanding of how people do their work. There is always a gap between the work as we imagine it to be and what it actually is. The narrower that gap, the more effective our changes are going to be, so focusing on understanding all the nitty gritty details of work and their pressures is going to prove more useful than having super solid numbers
- psychological safety is always essential; the thing that lets us narrow the gap between work as done and work as imagined is going to be whether people feel safe in reporting and describing what they go through. Without psychological safety and good blame awareness, you're going to have a hard time getting good results.
Overall, the idea is that looking for understanding more than causes opens up a lot of doors and makes incidents more valuable.
* I can't legally call myself a software engineer, and technically neither can I be a site reliability engineer, because Quebec considers engineering to be a protected discipline. I however, do not really get to tell American employers what they should give as a job title to people, so I get stuck having titles I can't legally advertise but for which no real non-protected forms exist to communicate. So anywhere you see me referred to any sort of "engineer", that's not an official thing I would choose as a title. It'd be nice to know what the non-engineer-titled equivalent of SRE ought to be.