Interval Tree Clocks
I wanted to gather some notes I've kept in my head over the years about Interval Tree Clocks. Interval Tree clocks have been presented in a 2008 paper by Paulo Sérgio Almeida, Carlos Baquero, and Victor Fonte. It's one of the most interesting and readable papers I've seen, but I don't recall seeing many production systems using the mechanism, and I'm not fully sure why. When discussing it over the years I realized a few times that I had come up with a pattern that made it possibly a bit more practical than what others had in mind, but never really wrote it down.
I'm not an academic, and I put zero formalism into any of this. The stuff I'm writing here is just me going "that sounds like it should work" and that's as far as I'm gonna go with it.
What are Interval Tree Clocks
The paper is really great because the authors were not content with only the math proving its soundness, they also use a great visual representation of the data structure to help understand it:
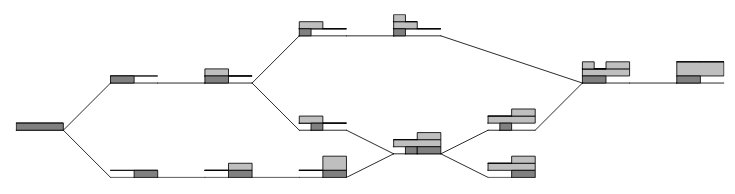
The way interval tree clocks work is fairly equivalent to vector clocks in that you can track causality, figure out conflicts, and so on. It however differs in one major way, which is that it is intended to be used in very dynamic environments where cluster membership may change constantly.
The trick for that is to base the clock on an Id that is divisible between nodes, such that any single member of the cluster can subdivide its own key space and hand a fraction of it to another one (as a fork), or to reunite any two of them together (as a join).
The first initial ID is always 1:
1 = ████
When that ID gets forked, it becomes two distinct halves:
{1, 0} {0, 1}
██▒▒ ▒▒██
If I fork the one to the left again, I now have 3 IDs:
{{1,0},0} {{0,1},0} {0, 1}
█▒▒▒ ▒█▒▒ ▒▒██
These three Ids are still unique, and remain perfectly mergeable or subdivisible again. I could, for example, join the first ID with the third one and obtain:
{{0,1},0} {{1,0},1}
▒█▒▒ █▒██
Where the second Id now absorbs the identity of both previous values.
The ID is only half of the clock, though. The clock works by incrementing counters by basing yourself off the Id. Only when both components are around do you have a full interval tree clock timestamp.
Let's take a look at the image from the paper, with annotations on it:
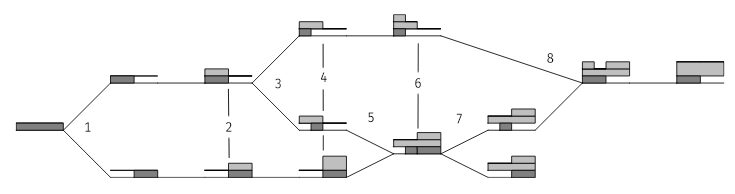
You can see the Id in dark grey below the dividing line, and the event counter on top of it. At step 2, both nodes increment their counter because they have seen an event or modified a thing.
The paper defines the following operations on a timestamp, which may help explain how the previous image works:
- fork: takes a clock and makes a new representation of it where the event counter is the same, but the ID part is divided as above. This is what happens at steps
1,3, and7 - event: increments the counter on top of the clock, based off the clock's id. This is what happens at
2,4(bottom), and6(top). - join: merge two timestamps and get a new one. This is what happens at
5and8 - peek: creates a copy of the timestamp, but with a NULL id, such that the event counter may be read, but not incremented. Not shown on the diagram.
- send: atomic composition of event+peek. Also not shown
- receive: atomic composition of join+event. Not shown either.
- sync: atomic composition of join+fork. This is not shown on the diagram, but can be thought of as leaving the IDs as they are, but merging the event counter.
All clock operations can be thought of as combinations of these commands.
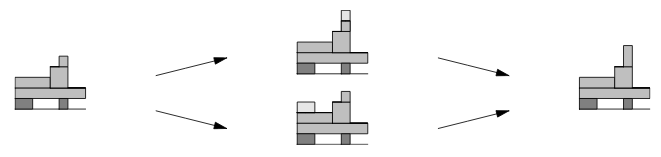
The algorithm becomes more efficient since it can handle its own equivalences in the clock component to reduce its complexity and size without loss of information:


Because the Id space is assumed to be non-overlapping between cluster members, the last image shows that you do not need to increment all the space matching an ID, just part of it. In this case, the algorithm ensures that the data set's numerical representation is more compact while incrementing the counter value and adding information to it. Here's another example from the paper:
The real world is tricky
The problem with ITCs is that it's kind of difficult to translate the data structure and its operations into a functional system if you've never dealt with that stuff.
The first time I looked at them, I was discussing it with a friend on IRC and we were just scratching our heads trying to figure out how we should actually make use of that stuff with a simple key/value store, since those are generally easy to reason about. Here's a few questions we asked.
Do you use one id per record and each record and then increment the events from there? This could seemingly work in this scenario with nodes A and B, and a user interacting with any of them:
- The user writes the data to
A, which creates ID1 = ████, increments the counter to1 = ████also. - A synchronizes with
Bby forking the stamp, giving IDs{1,0} = ██▒▒and{0,1} = ▒▒██. The counter remains1 = ████. - The user writes data to
B, which incrementsB's counter to{0,2}.
Then we're able to sync. The problem happens whenever we swap steps 2 and 3 however:
- The user writes the data to A, which creates ID
1 = ████, increments the counter to1 = ████also. - The user writes data to B, which creates ID
1 = ████, increments the counter to1 = ████also. - The system can only assume both data sets are equivalent since the clocks are the same.
Clearly we can't dynamically create the ID for each record if the interaction isn't done strictly with a single node to which to write (sticky). The scheme may be good to track the progression of a log through systems (since there's usually a single entry point), but not general enough for a key/value store, as one of the explicit requirements of the algorithm is that the ID space does not overlap and we can easily break that requirement!
So what we need is to guarantee a rule stating that only distinct IDs exist in the system, which means we cannot just create IDs whenever we want. We concluded that the ID division has to match each node's life cycle rather than a record's.
So we could just attach a seed ID to the node itself and ask a peer to fork off their ID. One has to be careful that the cluster is first initialised with a single root node at first, to avoid the case where we boot a new cluster with many nodes, two of which start at the same time and both assume the same ID.
Once a root node is booted, any other number of nodes can start joining by asking any other peer for a fork of their ID.
This logically works well, but has a hidden cost: if you keep timestamps as described in the paper (id + event counter) and the node splitting its own ID has 10 million records, you have to rewrite these 10 million timestamps right away. If you don't, the following scenario is possible:
A: {1,0} = ██▒▒ B: {0,{1,0} = ▒▒█▒ C: {0,{0,1}} = ▒▒▒█
--------------- ------------------ -------------------
K1: ████ K1: ████ K1: ████
██▒▒ ██▒▒ ██▒▒
... ... ...
KN: ▒▒██ KN: ▒▒██ KN: ▒▒██
▒▒██ ▒▒██ ▒▒██
So what's up there? Well each entry in the table that is synchronized has not been forked and shares the same ID. Any write would reuse the same ██▒▒ node ID and increment events in ways that do not track causality. Whenever A increments K1 things work, but if it starts writing to KN, it will look like an old version of B wrote to it, which would clash with what B and C could currently do. Rewriting each entry after forks (either right away or before access time at a later point) would yield a safer:
A: {1,0} = ██▒▒ B: {0,{1,0} = ▒▒█▒ C: {0,{0,1}} = ▒▒▒█
--------------- ------------------ -------------------
K1: ████ K1: ████ K1: ████
██▒▒ ▒▒█▒ ▒▒▒█
... ... ...
KN: ▒▒██ KN: ▒▒██ KN: ▒▒██
▒▒██ ▒▒█▒ ▒▒▒█
This now lets each node independently modify timestamps while tracking causality, but rewriting the whole table each time you fork a node would be extremely costly and annoying to keep track of.
A far more elegant solution is to break down the clock into its two independent components: the node stores the ID globally, and each record only contains the event counter. At each operation, we dynamically reconstruct the timestamp by submitting the node's ID on each operation, and the event counter on the rest. Since the event counter is monotonic and that the node ID changes rather rarely, we can get something that is a ton cheaper and simpler to manage that way.
This requires us to extend the design of the interval tree clock a bit to support 'explode' and 'rebuild' operations, which split up and rejoin a single ID+event counter part of a clock. With this design, we can move ahead and define the following (informal) protocol.
Protocol
In order to be effective, the protocol asks us to break a few layers of abstraction. This is usually a bad idea, but the tradeoff of having all layers know they're carrying interval tree clocks tends to outweigh rewriting all entries on each ID split.
The first step to handle is ID propagation, where a given node in the cluster allows another one to join in and start incrementing events.
ID propagation
- The cluster must be initialised with a single root node given the ID 1.
- Any node joining the cluster after the fact must contact at least one other peer and ask for a fork of its ID. Ideally the peer is chosen randomly to avoid subdividing the same part of the ID indefinitely, giving suboptimal id spaces.
- The existing (forking) node reads its ID from storage and forks it in memory
- The forking node picks either side, and overwrites its existing ID value in permanent storage (it should then wait for all ongoing operations with the old ID to terminate)
- The forking node then sends the forked ID to the asking node.
- The joining (asking) node stores the id to disk
- Any node leaving the cluster may, in order to help reduce the ID and event space:
- stop accepting writes
- synchronize its data set with the rest (or part) of the cluster (see Data propagation below)
- Read the local id from persistent storage
- Delete the id from persistent storage
- Pick one peer node at random and give its ID back to it for it to be joined into its own. The other node can accept the ID directly. In case of failure or timeout, do not retry to send the ID; it is simply lost. You may want to log it somewhere so that an administrator can reconcile values manually later on.
Step 2 has to happen in that order to prevent the case where the forking node sends a split id to the remote end, then crash-restarts or loses track of the change. If that happens, causality for the whole cluster is thrown off the mark as ID spaces now overlap; causality is corrupted.
Step 3 has to see steps c, d, and e happen in that specific order to avoid crash-restart scenarios possibly asking the same ID to be joined on various remote nodes at once. This would create conflicts and corrupt causal relationships to come. Steps a and b are optional (or could be interspersed with the other steps), but nevertheless good ideas to avoid data loss, if any.
Data propagation
From this point on there's a fork in the road depending on whether you want equivalence with version vectors or vector clocks. They're the same but different.
Basically, the same logical clock mechanism can be used for either purpose. The distinction is in the intent of what you want to track:
- If you want to track the causal ordering of modifications to a data set (i.e. data in a database), you want version vectors
- If you want to track the causal ordering of events in a system (i.e. track the information flow of "who has heard about this?"), you want vector clocks.
The distinction is fairly simple: for equivalence with a version vector, you increment the event-counter when data is modified. For vector clock equivalence you must increment the event-counter whenever a message is sent or received.
Even though the distinction is simple, it can have important consequences. If you only need a version vector, you can skip over a few update operations and gain some efficiency, or even look into variations such as dotted version vectors (DVVs) to account for changes on behalf of clients. Do note that although ITCs can be used as version vectors, they do not allow DVV-like usage. On the other hand, version vectors carry less information: if you ever want to make a Consistent Cut, they won't be as "accurate" as a vector clock would be.
So this yields this new bit of protocol for the rest.
Version vector equivalence
- When reading data, simply return the data and event counter
- When writing data, increment the event counter
- When pushing data to synchronize it, only send the event counter to the remote node for each entry, but not the ID.
- When receiving data:
- fetch the current stored stamp for a given entry (if any)
- if the current stamp is >= the received one, do nothing
- if the current stamp is < the received one, store the new one with the new piece of data
- in case of conflict, two options exist, either on resolving conflicts on the spot, or tracking conflicts. Both options can be tracked under a single clock however. To run that one, simply join both clocks. Because we only have remote events, we can simply call:
{_, EventCounter} = explode( % only grab the event, we know the ID already event( % increment the event counter join( % merge the event stamps peek(rebuild(LocalId, RemoteEvent)), % complete the remote stamp as read-only rebuild(LocalId, LocalEvent) % make a complete local stamp )) ).
For step 2, one thing to pay attention to is the client. The client is part of the distributed system if it is external to the node. If writes come from such a party with no clock information, we cannot necessarily assume that it is aware of an existing piece of data or conflict unless it submits an event counter with it. We essentially have to consider a client like that to be sort of a rogue participant into the system. To make the client behave, it has to be able to submit a stamp, and to have the client submit one, it must first read the data, where we may assume an acknowledgement of its content. If an event counter is submitted back when writing, we can do conflict detection at write time. If none is submitted, we can either always crush the entry (last-write-wins), or declare a conflict to be resolved later.
The last sequence, described in 4.d, is interesting. Because we only have three pieces of data (local id, local event, remote event) and are missing one (remote id), we substitute in our own local id to go with the remote event, and then use the 'peek' primitive to give us back a mergeable event clock with a null ID. We then join them back together which gives a full local clock that is up to date. Because we either picked a winner or started tracking conflicts, the data has changed and we must increment the event counter. We can then extract that part to store it.
This stamp is now greater than either of the basic ones, and the increment will ensure that any third party that had either copy will now get theirs crushed (or will now see a conflict too, if they had made modifications).
Vector clock equivalence
For vector clock equivalence, only steps 3 and 4 need to change compared to the version vector approach:
- When pushing data to synchronize it, increment the event counter and store it. Then only send the event counter to the remote node for each entry, but not the ID.
- When receiving data:
- fetch the current stored stamp for a given entry (if any)
- if the current stamp is >= the received one, merge both counters and increment it with the local id before storage
- if the current stamp is < the received one, store the new one with the new piece of data, but merge both counters and increment it with the local id before storage
- Same as for vector clocks
The distinction is that any act of communication now increments the event counter.
Backups?
Restoring from backups isn't something I have given much thought in such a case. The data set should be safe to restore, as event clocks are monotonic and should be able to stand on their own for comparisons (as shown in step 4.d of data sync). However, it is risky for any node to be restored if it had previously removed itself from the cluster since it could start corrupting timelines by using either an id that is either a duplicate or a subset of an existing one.
If it is not possible to say with full certainty whether the ID was still active and not retired, abandon the ID. The id space will grow fairly indefinitely, but at a much smaller space than it would have had with a version vector or a vector clock anyway.
My assumption is that at that point in time, you'd want some auditing mechanism that can find IDs that were allocated but are no longer used, and fold them back into the ID of a running instance. To keep backups functional, I'd expect someone to wait for a given delay before reaping the IDs. For example, if you take daily backups, it might make sense to assume that you wouldn't bring back an instance that is a week old when you have half a dozen new snapshots, and it would be safe to reap their IDs. In the case where you still need access, you'd fall into a pattern of data-recovery where you would have to do some fancy stuff by hand (i.e. rebooting the instance with a new forked ID while keeping the old events and seeing how many conflicts that creates).
I haven't checked really what would make sense there, but I'd have to assume that someone shipping such a system might want to support "consume-only" modes where a node brought back from backups will try to sync data from peers locally only to check for conflicts, before actually trying to ship all that data to other nodes and propagating potential clashes.
Conclusion
I don't expect a massive pick up of what this paper proposes now that I've written this—there would be a need for far more formalism than what I know how to do for that—but I'd like to see it read more often. One of the really great things it promises is the option to do eventual consistency in "mostly offline" settings with a very limited ability to know how large the actual cluster is.
CRDT research is where most of these efforts went over the last few years, but I don't know that it's always the safest way to handle things. It certainly makes sense when you're building a collaborative tool where you control the experience and artifacts end-to-end. In many cases, changesets are not necessarily mergeable in a monotonic way and detecting conflicts is a good thing. One example of that might be artifacts produced by systems that do not care about structurally being mergeable, such as versions of rendered documents or videos, or form data where conflicting entries by different people can't be safely reconciled and require domain-specific resolution, such as what I imagine could happen with prescription drugs.
I've personally been toying with the idea of making a sort of peer-to-peer dropbox on the side for years (on-and-off) and never really getting far because I keep being distracted into doing other stuff, but I always imagined that interval tree clocks would be the right data structure for that.