Paper: Visual Momentum
Today's paper, Visual Momentum: A Concept to Improve the Cognitive Coupling of Person and Computer is a David Woods paper he framed as follows on Twitter:
todays HCI [Human-Computer Interaction] has very very low visual momentum. Tech companies think this is good; Ops worlds have to do workarounds so much they think this is normal & necessary. Neither is true. design has gone backwards
Woods wrote this paper in the 80s but this recently decided to call out tech companies on our terrible Human-Computer Interfaces (HCIs) in a tweet quoted above, for having “low visual momentum”
He defines visual momentum as “a measure of the user’s ability to extract and integrate information across displays, in other words, as a measure of the distribution of attention” and states:
When the viewer looks to a new display there is a mental reset time; that is, it takes time for the viewer to establish the context for the new scene. The amount of visual momentum supported by a display system is inversely proportional to the mental effort required to place a new display into the context of the total data base and the user’s information needs. When visual momentum is high, there is an impetus or continuity across successive views which supports the rapid comprehension of data following the transition to a new display. It is analogous to a good cut from one scene or view to another in film editing. Low visual momentum is like a bad cut in film editing—one that confuses the viewer or delays comprehension. Each transition to a new display then becomes an act of total replacement (i.e. discontinuous); both display content and structure are independent of previous “glances” into the data base. The user’s mental task when operating with discontinuous display transitions is much like assembling a puzzle when there is no picture of the final product as a reference and when there are no relationships between the data represented on each piece.
He says that not doing this right tends to often show up in ways interpreted to be “memory bottlenecks,” where people get lost in their displays and information. He warns that those are not memory issues, but symptoms of mismatches of the human-machine cognitive system (the machine isn’t being helpful or playing to the human’s expectations and the human is adjusting)
Woods writes in a dense style (colleagues describe it as "Woodsian"), but if I get it all right and reword it briefly, he states that humans are good at spatial cognition and that playing to that strength reduces the cognitive cost of dealing with information. The layout and transitions for displays/graphs/charts/whatever can be used to give information about what the data they contain represents and how it connects to the rest; not doing this means that we must use a different costlier type of attention to keep track of everything mentally.
He creates a gradient of visual momentum sources, and defines each of them, using ‘maps’ as an abstract metaphor (you can think of them as literal maps, but also just as “organization structure” and he seems to hint at the latter):
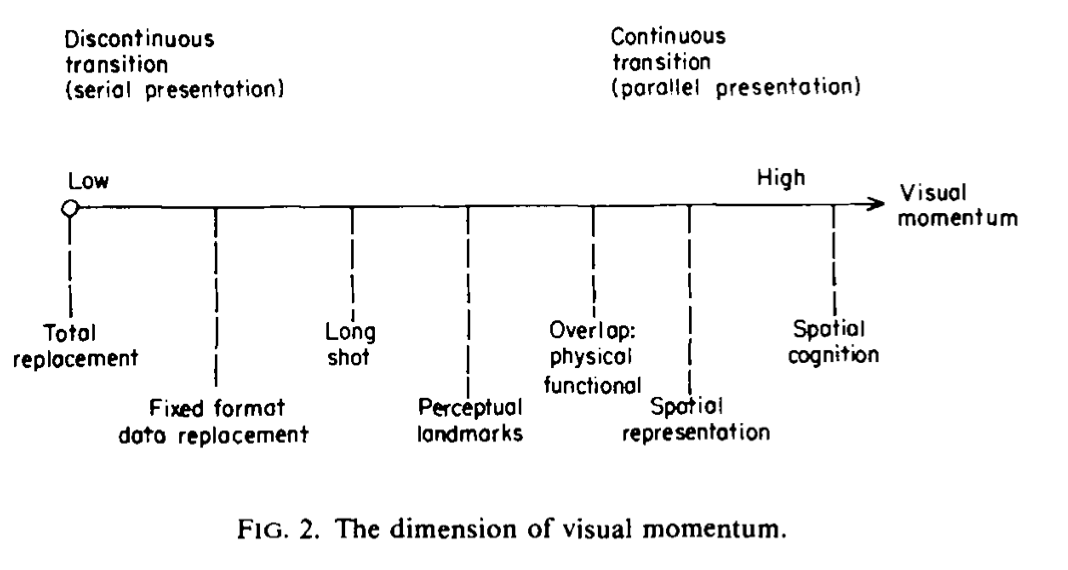
My interpretation of which is:
- total replacement / fixed format data replacement are just flashing a new page
- long shot is about providing a summary view of status that contextualizes later views or direct digging from there
- perceptual landmarks is about providing contextual cues for a display to lead to another such that you could follow information across locations
- display overlap is about using layers to show multiple sources over a single visual framework, tied together by function. Inherently more limited due to the presentation surface (I’m having a hard time breaking out of the “map” analogy here, but I could imagine being able to highlight the data path probed by some user-facing alert to contextualize components involved and their state)
- spatial representation is about making use of the layout of presented data to also provide further information about their meaning and the location you’re in right now. He mentions navigable topologies of databases info, route knowledge (and breadcrumbs), maps to supplement menus, etc.
- spatial cognition: finding ways to represent systems through analogies of ‘routes’ that can be selected and navigated, since these can be laid out and considered in parallel; it requires a spatial framework that focuses on relationships between components
It’s followed by a short discussion on the way people process such information, and the iterative nature of sensemaking compared to the cost of navigating displays while holding on to context.
Anyway, I found that paper super interesting in the context of “y’all computer ops folks have shitty support for people overviewing a system and it takes a lot of cognitive load”, and there's a lot to think about in terms of how much of our systems never really go past the first few rungs on that ladder. It's worth reading if you're looking at providing better support to humans working with computers.