Operable Software
Operability and observability sure have led to a lot of blog posts around the web lately, and so this is my take on it. In this post, I'll cover views on simplicity and complexity, how people actually approach their systems and form mental models of them, and how we should rather structure things if we want to make systems both observable and operable. Or put differently, how to start approaching Operator Experience.
Thanks to Cindy Sridharan, @di4na, and @rotor for reviewing this post.
Simple is Complex
One of the most common piece advice a developer receives is to keep things simple. Prevent complexity at all costs. Debugging code requires you to be clever, more so than when you wrote it; therefore, if you were being clever when you wrote it the first time around, you'll need to be doubly-clever to debug it. By keeping things simple the first time around, debugging and fixing will be easier.
This is good advice, but "complexity" is an ill-defined term. I won't even attempt to define or clarify it here. Instead, I'll start with what at a high level should be a rather simple system:
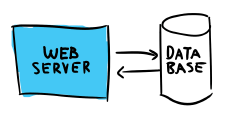
At first view this is straightforward. You got a web server, it supposedly receives requests, asks the DB for info or writes to it, and then returns some response to a client. This is usually as simple as a web app can get. You can assume the server is stateless and can just be replaced without risking anything.
The mistake here is considering that the system is limited to the high-level components we directly write. You could, for example, take this view:
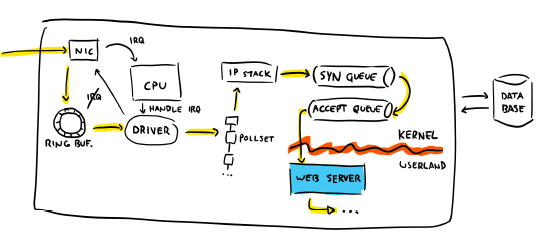
This is a high-level vision of how packets in a TCP connection flow in the Linux kernel. You don't necessarily know it exists, but it's there. You have to answer for it, and be on call for it. You may not like the responsibility, but if things go bad and fixing it is up between you, the product manager, or the HR department, you bet your ass you're going to be the likeliest individual to dive in.
And this is still a rather simple vision: we haven't considered that you're probably running in the cloud, so you might have a hypervisor, and then maybe containers on top of it. You may also have firewall rules and we still have not yet looked into what "web server" should be doing.
There's an argument to be made that simple systems existed in the 60s and 70s, when the computers were small enough that you could know and understand everything that was going on. This is no longer the case for people working on back-end systems in the cloud.
But this is a bit disingenuous, because I'm playing with the layers of abstraction we have:
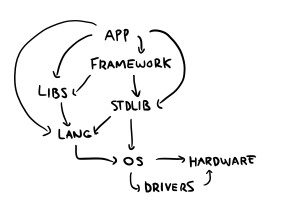
In practice, "keeping it simple" is advice targeted at the top layer here, the application layer. We operate under the assumption that with proper abstractions, we can ignore the underlying complexity of the lower layers and build on top of them transparently.
This is kind of impossible according to the Law of Leaky Abstractions, but fine, let's accept this vision and go back to our top view:
It's possible that this system won't work at all, but chances are you can make it functional. It is however not necessarily a reasonable architecture. If you have an online store and you get 15 visits a month, it's probably fine; anything more complex would be preposterous. On the other hand, if your online store has thousands of visits a second, dozens of employees whose livelihood depend on it being up and working, and scores of commercial partners counting on you, then having this same exact architecture would probably be considered extremely irresponsible.
A more reasonable architecture for something of that importance would try to cope with the most predictable failure cases, and we would probably end up with something closer to this instead:
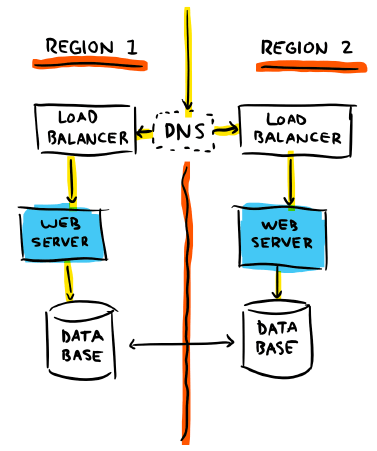
You'd want to go for a multi-region setup, with some form of load-balancing across regions—DNS in this case—and a few load balancers within each region to dispatch to various web server instances. This kind of complexity becomes unavoidable as your product becomes popular and your system grows in demand and expectations. You will build these features as you find out about new issues and how much of an impact they have on people who rely on you. Not doing so will lead to frustration on their part and will prevent further adoption.
Basically, you should probably not write the multi-region version at first; it would be quite tricky to get right the first time around and see all the problems ahead of time—even if you've encountered them before, since they don't apply the same to all systems—and the reasonable approach is usually to indeed start from the small system, and grow it as you go. And even doing that can be very risky, as demonstrated by the Second-system effect.
In any case, since you're now working in multiple regions, your database strategy needs to change as well: not all of the data can be available everywhere at once. What could have been a simple report to write (just SELECT ... FROM ... on the sales table) may now need to cover data that won't fit memory, go across regions, and some features may not be possible to make efficient anymore. The additional robustness of the system comes at a cost in terms of complexity and flexibility.
You have to revisit features as the system grows. As it gains necessary complexity in order to scale (and most probably accidental complexiy as well), its behaviour changes. No large system behaves the same as a small system, even when they fundamentally aim to perform the same task. No large system behaves the same as a small system, even if the small system itself has grown to become the large system.
Do note that behaviour is not only limited to features: it also includes failures. The failure modes and domains of the small system (one node freezes or goes down) are entirely different from the failure modes and domains of the large system (data synchronization issues, cross-region configuration problems, partial netsplits, and so on). It follows that the people operating such systems have to adapt as well.
In short:
- A simple system can work (but is not guaranteed to do so)
- A complex system can work, usually if it has been grown from a small system. Trying to ship a complex system the first time around is usually not gonna go great
- Complexity is unavoidable as your system scales; If people rely on a system for something serious, it will inevitably become complex
- A simple system behaves differently from a large system, even if both provide the same functionality
So the question we should ask is not how to prevent complexity, but how to cope with it.
The Need for Observability
If we want our system to be reliable, we need to know when it misbehaves and when there are bugs.
The general approach for this is monitoring. In a nutshell, monitoring is the act of asking your system "how are you doing?", and checking for a response ("I'm doing fine!", "something feels odd", or just no response at all). We'll usually do monitoring through simple inputs and outputs:
Common patterns may include opening a socket and seeing if it gets accepted, sending an HTTP Request and seeing if you get a 200 or a 500 back, calculating response times and making sure they fit a given threshold, and so on. We poke at it, check the result.
Monitoring generally tells you only whether something is wrong, but not what is wrong, nor why it is wrong. It is ultimately knowing that the system has a fever, but not knowing what the disease is.
The identification of a fault is more generally resolved through observability. Whereas monitoring asks "how are you doing?", observability asks "what are you doing?".
Observability comes from control theory—self-regulating systems such as speed control on a car, or flight stabilizers in airplanes. The gist of observability according to control theory is that by looking at the outputs of a system, you can infer its internal state. This results in the same view, but now you know what's inside:
Now this may work fine with something like a thermostat, but we all know that software is not observable by default. If I send an HTTP request and get a 502 Bad Gateway back, I certainly won't be able to figure out what exactly is wrong. In many cases, we in fact actively avoid showing the users what is going on, and want to make it "just work" and look like magic. But when it comes to operations, we want to ourselves have the ability to figure out what's going on inside. So what we do with software is cheat. We cheat by adding all kinds of windows to our black boxes and using logs, metrics, and all kinds of debugging tools to create new outputs that are visible only to us, and not the users:
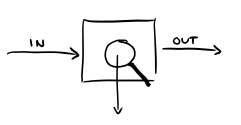
What we end up with is a kind of "behind the scenes" backstage pass for our operators. And just like that, we create enough new outputs that we can try and pretend to be as observable as control theory systems; we can now infer the internal state of our systems through observing their outputs without messing with the user experience.
How would that look in our system? Let's get back to the simple system view, as it makes things a bit easier to reason about:
We've got components missing for sure. How is the code making it on the machine? Where are the logs and the metrics? A more reasonable view of the system might be this one:
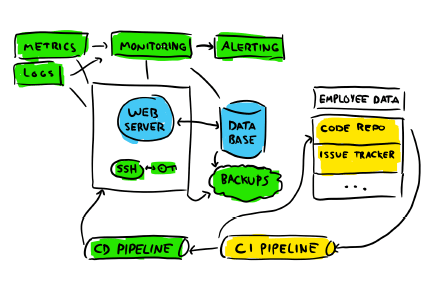
If we want to have monitoring and observability, we need to add most of the green components. They represent various interfaces and facilities related to deploying code (how else are you going to set up the environment?), storing and consulting logs and metrics, and gaining access to servers we own. The yellow components are a bit of a logical deduction: if you've got code to deploy, the code has to come from somewhere. And so there surely are some repositories here and there in the organization, and a list of bugs and expected features. Knowledge about the system's code has to live somewhere.
But the view still isn't complete. We're missing the people:
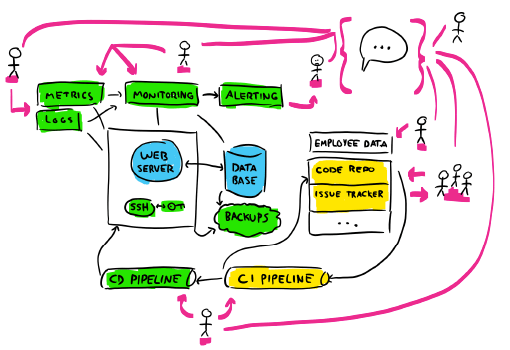
The people here are a critical component, because they are those who interpret the information, decide what is worth investigating, and who decide to change the system either directly (by changing configs and manipulating its state) or indirectly (by writing programs or agents that care for the system on their behalf). Everyone of them will have an impact, even if they don't touch the code directly. We have that person at the top right who doesn't touch code, and yet they still can do a lot: they could be part of the sales staff that promises features, or an exec who sets a new direction or priority for the system. Their understanding of the hardships of the system can impact what ways others can change the system.
Because people are the main actuators, creators, and interpreters of the system, they have to be considered part of the system itself as well. They must be part of the diagram. Their knowledge of history and context, their authority over some components, and the relationships they have with other people and parts of the system all have a real potential to dictate and impact its behaviour and future.
But let's get back to our bug. We've got monitoring that triggers an alarm because a given metric has broken a threshold (chosen by one of the humans). Who gets the alarm, and where do they start? Are there procedures, metrics, observational pieces of data that they consult? Which one should they even consult? That should be part of their training! Are they even trained? How do we choose the training material?
Those are all very tricky questions, and it turns out they're critical in making resilient systems. The code can be a dirty mess, but if the operators understand it well, it can work fine. The code can be a pristine marvel of engineering, but if operators are confused as to how to operate it, it can be a massive failure. A critical variable here is the understanding various humans have of the system as a whole.
Mental Models
To characterize people's understanding, we'll have to take a look at the idea behind a mental model. A mental model is an abstract representation of the world that we build based on various observations and a priori knowledge.
It is tempting to look for perfect mental models, and how to teach them to people. The problem is that this is just impossible to do; it's also not really necessary. To illustrate that point, let me refer to this map:
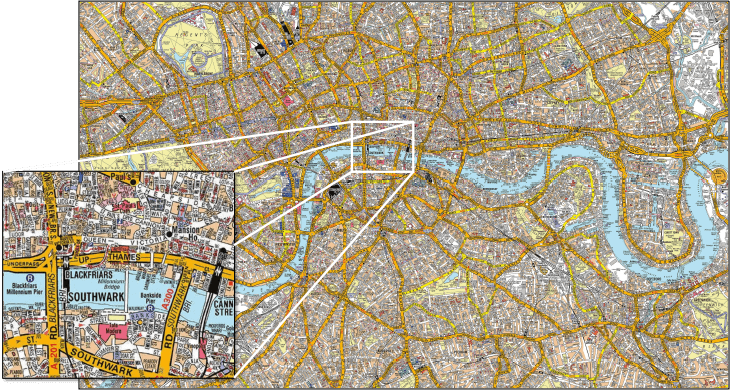
This is a map of the city of London, UK. It is not the city of London, just a representation of it. It's very accurate: it has streets with their names, traffic directions, building names, rivers, train stations, metro stations, footbridges, piers, parks, gives details regarding scale, distance, and so on. But it is not the city of London itself: it does not show traffic nor roadwork, it does not show people living there, and it won't tell you where the good restaurants are. It is a limited model, and probably an outdated one.
But even if it's really limited, it is very detailed. Detailed enough that pretty much anyone out there can't fit it all in their head. Most people will have some detailed knowledge of some parts of it, like the zoomed-in square in the image, but pretty much nobody will just know the whole of it in all dimensions.
I would compare this to our understanding of the systems we work on: we tend to have some intimate knowledge of a narrow section of it, but not the whole thing. You're likely not aware of all the linux drivers each of your node uses and you don't necessarily know who works in the accounting department. You may or may not be aware of who knows about the sections you know little about. And keep in mind that the source code is not the system; you probably ship compiled artifacts that run in an entirely different environment with specific configurations on hardware you don't have on your desktop.
In short, pretty much everyone in your system only works from partial, incomplete, and often inaccurate and outdated data, which itself is only an abstract representation of what goes on in the system. In fact, what we work with might be more similar to this:
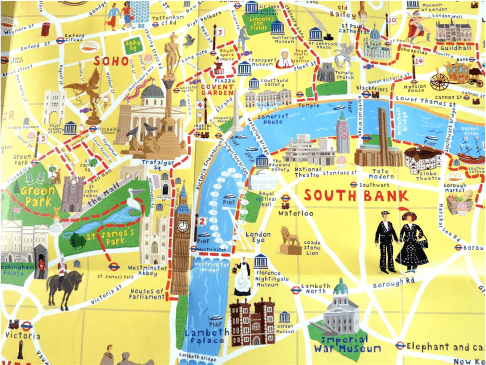
That's more like it. This is still not the city of London, but this tourist map of London is closer to what we work with. Take a look at your architecture diagrams (if you have them), and chances are they look more like this map than the very detailed map of London. This map has most stuff a tourist would want to look at: important buildings, main arteries to get there, and some path that suggests how to navigate them. The map has no well-defined scale, and I'm pretty sure that the two giant people on Borough road won't fit inside Big Ben. There are also bunch of undefined areas, but you will probably supplement them with other sources.
What's interesting is that if someone asked you "I want to go see the Tate Modern, how do I get there?", you would be a much better guide if you gave them the tourist map than if you gave them the very detailed map. Chances are the detailed map is going to give them major information overload.
Since a map is pretty much just a model of a city, you can see why I chose them for this analogy: it is not because a mental model is incomplete, outdated, or even slightly wrong, that it will prove more useful than any other one. Especially during a production incident where part of the system is dying, the ease with which you can reason and make acceptable decisions can be as important of a factor than how correct the decision is; it might be better to take a somewhat good action now than making a perfect decision later.
In practice, our models are created, invalidated, and updated as we evolve with the system and keep putting them in practice. Some things are going to be wrong, and you'll have to change what you see about the system. If you take the two maps of London, there's a chance that the neighbourhood you live in will be super detailed, as will be the neighbourhood around your workplace. Everything else in between might be like the tourist map.
And this is going to be fine, because that's how you evolve in the city, and that's only as much understanding as you need. To drive the point through, let's look at this other map of London:
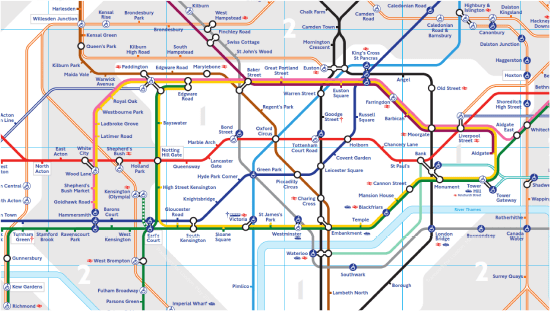
Now that's an interesting one. It contains no streets, no buildings, no tourist attractions, and the locations and scales are all bad. It is, by all means, the wrongest of maps. Yet, this map likely lets you get much further through the city than any of the previous versions, and faster. It contains a more compact description than other models if you want to connect to other parts of the city, and pre-supposes that you have other maps or knowledge to refer to already.
What I want to point to here is that various people in your system will build the equivalent of these maps based on their everyday interactions with various components of the system. None of the mental models are complete, all are slightly outdated, all have blind spots, and all of them can be described to be wrong in different ways. You can educate and inform people, you can train them and force them to keep things up to date through practical exercises and fire drills, but they are always going to be incomplete, outdated, and wrong. They build their models inside their heads, and while you can try to influence it, you can have no direct impact.
But that's fine. You don't need perfect information and perfect understanding, it just needs to be good enough. A model is useful when it has good predictive value. If you can figure out what's going to happen before events unfurl, your model is going to be satisfactory. If the model is not good enough at predicting things, then your operators are going to have a surprise. Those surprises are what forces us to revisit and improve models. We intuitively know that if we can't predict the outcome of a situation, we have to adjust our understanding. But until such a surprise though, we're at risk of just missing changes. Models work until they don't.
For example, if you live in a country where temperatures are always between 10°C and 25°C, you may be surprised when some machine of yours with a water-based cooling system suddenly breaks down while turned off because it got below 0°C during the night and all the pipes burst. Suddenly the model of “always works fine” becomes location and weather-dependent and may even suffer mechanical breakdowns while not in use. That’s a shock! Now your system is no longer your own machine, but must include heating elements and HVAC systems, may have to care for the power grid, and so on. That’s a major scope change due to previously overlooked variables.
What's interesting from this idea of a mental model is that it lets you imagine various ways that guide how we debug a production system. Let's get back to that top-level system view:
Maybe that the person on the top left, the one with metrics and logs, imagines the system far more in terms of data flows and interconnections between components. That might be comparable to the tube map. When there's an incident or a bug report, they will look at where data is coming from, where it stops, and some quantitative metrics to interpret what goes on.
If you're one of the three people on the right and you tend to work with code, you may rather ask questions like who changed code recently? Maybe you know that someone on another team was working under pressure to ship something late, and they might have made a mistake. Maybe a changeset was pushed to prod and done by a developer you think is really bad and you don't trust them. Or maybe you trust them, but you know that some part of the code is really messy but nobody had time to improve it, so surely the issue sits in that shaky part of code.
The model you have and the perception you have of the system is one of the most important driving factors that will point you towards your own debugging procedure. This is, in my opinion, one of the reason why DevOps is important as a practice: you at least want some developers to be able to narrow the gap between development and operations, to understand both worlds, and to act as a bridge between the various understandings. It's an organizational pattern that helps enrich everyone's model by bringing the perspective of others closer to you.
This also can help decide how to instrument code. If your codebases are like those I worked on, a huge part of your logs and metrics are chosen arbitrarily. Often they are obvious and basically given to you already (CPU, memory, I/O metrics, and things like HTTP request logs), and another large part of them is that developers put a bunch of visibility into the parts of the code they are nervous about.
Those would be places where error handling is kind of oddly defined or uncertain, where unexpected conditions might arise, or where bugs showed up in the past. To shorten investigations, we add more visibility there because we guess that this is where things will go bad.
How to Structure Observability
A lot of people seem to have a good idea of what observability should be about—mechanisms by which we understand how our programs work. What's trickier is figuring out how to do it right. What we tend to do is "guesstimate" where probes should go based on the bugs we've had, and those we think we might encounter.
Let's say our app is this house:
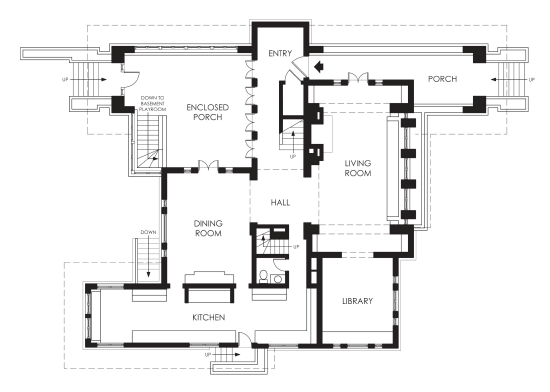
When we have no instrumentation for observability, just a black box, what we have is essentially that house, without windows and just walls. Every time there's a tricky incident or bug, we have to investigate. Eventually, the solution is found, and what we do is add a bunch of logs that we wish we had before the investigation even began, adding windows to the walls.
We reason that were these logs available, it would have taken us only a few minutes to find the issue rather than days of investigation. Next time, if something similar happens, we hope it'll be easy. And so we add more and more visibility, until all the walls have windows:
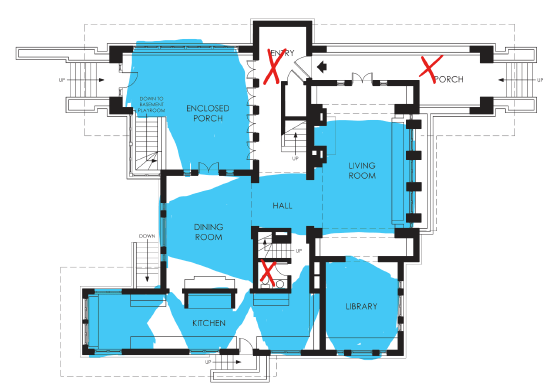
All the areas in blue are visible and observable through the windows. Those are places in our app where we have logs and metrics. You'll note that I have placed a few red Xs in there. Those are the places where we have no visibility, where the tricky bugs will show up next. They will show up there because had they shown up in the blue areas, they wouldn't be tricky since we'd have logs about them. It's tautological.
Essentially, tricky bugs are tricky because we don't see them coming. If all we do is pepper logs and metrics where we expect bugs or where they have shown up in the past, we will never really help future investigations; we'll only prevent repeating those from the past. It's closing the stable door after the horse has bolted.
If left unchecked, this results in what I like to call the software engineer's house:

A ton of ugly windows, put haphazardly. Sure you've got good observability, but it's a mess. At some point, observability takes over code readability and maintainability, and the amount of data shown, with all its hook points, can become an operational burden. What we need is a more systematic way to go about things.
This is where you'll hear people say "I know what we'll do: we'll make everything in our app observable." And this too can be pushed far. I've talked with some teams in the past who wanted to make absolutely everything loggable. Even network traffic. So they put debug logs around all network calls. Of course, network traffic was very expensive to log, and needed to be turned off by default. But if you needed to know what was going over the wires during an investigation, you could turn that on!
If we re-use the house analogy, it would be like building the entire house out of glass, that way observability is real easy:
While this is seemingly a good idea—who wouldn't want full visibility into everything?—with some nice architectural flair, it's actually counter-intuitive practice. The problem with the glass house where everything is observable is that it just contains too much information.
There's a lot of noise, and you can get what you want, but only if you know exactly what you're looking for, and where to look for it. It's a completionist model. You can only know what a specific log line means if you know where it comes from. If you don't know how the application works internally, it provides you no guidance whatsoever. If we think about the city maps, the glass house is throwing the fully detailed city of London map at you, while what you might need is just the tourist map. This is especially true during incidents, where quick reaction times might be critical.
For example, messages about running out of file descriptors mean little if you don't know what the file descriptors are needed for in the first place. But even then, that's kind of easy if you have seen such errors before and you have an idea of how a program might use file descriptors. Sometimes, it's not so easy: a coworker once had to work from a log line from Linux that just said skb rides the rocket: $n slots (it's a driver bug with TCP Send Offload, it turns out). Without context and a model in which to interpret events, most of the information obtained through a glass house system will be meaningless at best, and misguiding in the worst cases.
In fact, if you don't already have an established mental model, a glass house view is so noisy that it's basically impossible to build one. Everything correlates with everything, and the best you can do is poke at things randomly until something appears to work. When you build a mental model, you have to be able to make observations, figure out how things work, and evaluate the consequences of your actions. A model's value is directly proportional to how accurately it lets you predict what is going to happen, and providing visibility into everything at once hurts more than it helps.
If you've ever met experienced operations people and asked them how they debug network problems, you know what they'll tell you? They'll tell you to use tcpdump or wireshark. They'll use some universal tool provided by the operating system that will work for any application whatsoever. You know what you will never hear? You'll never hear that they'll just go and reconfigure the application's logs to output network traffic it sees going through, and then they can just take their time to analyze the logs. That simply does not happen.
To make a long story short, the glass house provides too little guidance for people who do not know what they are looking for, and people who know what they are looking for will usually go for tools they know already and believe can help them. The glass house is only useful to the developers who wrote it or read the source code, and know where all the probes are. The rest of people will either be overwhelmed by the information or ignore it wholesale.
Instead, what we should do is go back to our layered view of all the abstractions we work with:
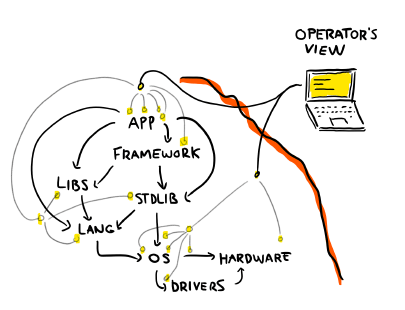
This is the same view as earlier, but with various probes added. As an operator, you never really see "inside" the system. You just have a bunch of tiny streams of slightly outdated data to report what has been going on.
If you look at how experienced ops people do things, you'll find that a lot of times, they use a bunch of probes that are placed at the operating system level. They might include things like DTrace and SystemTap, system logs, utils like perf, top, htop, netstat, and so on. These probes let you, as a user of the operating system, figure out how you and your programs are interacting with facilities of the system.
If you look at your web server, you'll see that you have logs about requests, responses, and possibly the configuration a web server is running (which ports is it listening on to, for example).
The thing that you can extract from this is that generally, logs, metrics, and tracing are not provided to explain how the thing you are using works: they are meant to let you debug your usage of it. Let me repeat that and put it in bold: most applications and components you use that are easy to operate do not expose their internals to you, they mainly aim to provide visibility into your interactions with them.
This means that if you want to make your system operable, you shouldn't aim to just expose all the innards you can. You shouldn't ask people to be aware of how you've implemented things. Instead, you have to think about who is consulting the data you expose, and why. We have entire departments dedicated to User Experience (UX), but nearly no concept of Operator Experience (OX, or OpEx?) even though operators keep the lights on and are critical power users.
So looking at the abstraction diagram above, the operating system should (and does) aim to provide probes that let us debug our interactions with it. Our programming language should give us tools that let us understand what we're doing with it—usually through debuggers and instrumentation in their VM, or DTrace probes when possible. The frameworks with which we build our applications should provide observability for us as application developers, so that we can better understand what is going on. And finally, your app should mostly expose operational data for its application users, not its developers.
This is important, because any layers on which we build that do not provide good observability for us, as their users, implicitly force us to compensate for their opacity at levels we do control directly. The glass house approach where the application logs expose everything that happens internally indistinctly is not an operational success story, it is the unfortunate consequence of building with inadequate tools and being forced to cope at the wrong layer of abstraction.
These abstraction layers, at the same time, provide the kind of "operator story" we want to guide investigations. First, check that the user actually does the right thing with the system-wide application logs (such as distributed traces and top-level logs and metrics). Most investigations end there. These probes make sense to place individually at key points that users will care about.
If the investigation goes deeper, then you'll want to check how the application itself works. Placing probes for this in the app itself is misguided because, well, the app is not trusty right now since we suspect it has bugs, and you will need to put logs everywhere. Instead, find a way to put probe points in the framework itself. If you use a web or RPC framework, for example, it might let you get information about all the middleware it runs and the values they return. For the framework, this is one small set of probes, but for you, as a framework user, it lets you get a quick view of everything that is going on. The cost-benefit analysis is clear; you get more bang for your buck—and a more maintainable app—when your tools support you operationally.
And if the investigation still goes deeper, then you can sure look at language-provided features, VM metrics, DTrace probe, OS tools, and so on. From experience or convenience, you may even start at a lower level anyway, particularly when you encounter performance issues rather than behavioural bugs. Then that provides a broad view, and from there you narrow down. This is particularly true when you know there is an issue with some functionality, and you just want to figure out who or what is using it. If you provide visibility into interactions before internals, then you allow people to jump in at any level according to their experience.
In fact, if you are hoping for operability, I would go as far as saying that when the layers you are building on don't support you in terms of observability, they should not be considered "the right tool for the job."
Feedback Loops and Empathy
The important lesson is that you'll encounter multiple types of operators, with various mental models, and various approaches to your system. You must take a human-centric approach. Avoid the glass house, and provide well-layered observability probes that adapt to specific types of concerns, and provide both guidance and flexibility to operators. This will be the difference between a system where people can operate at various levels of experience, and a system where only wizards can thrive.
You can't hope to instill perfect models in people, but you can still provide training and help them form more accurate models on their own as well. If you want to understand operators better, in order to do a better job of catering to their needs, there's nothing like being in their shoes for a while. When developing and finding hard-to-debug issues, try to resolve them with production operator tools, rather than your usual dev tools: see what's available to them, and what are the areas your stack renders difficult to introspect at run time.
If you find yourself needing to add observability probes, remember to put them at the right abstraction level. A probe added to the layer of asbtraction below the one you are currently debugging can provide insights for all interactions with that layer, and will likely be reusable for other bugs; this is the way towards generic tools.
Another interesting thing is to evaluate how easy it can be to come up with a model. I've been vocal about property-based testing lately, particularly stateful properties. Stateful properties are based on writing up a model of your software, which then gets validated by comparing it with the real program. If you have a hard time coming up with a good model that gives useful properties, your operators are likely also going to have a bad time figuring out what goes on in the system. I also suspect the same would be true of formally modeling things in TLA+ or when writing high-level documentation, but property tests are what I'm most familiar with in getting direct feedback.
I think that trying your hand at explicitly modeling your system or parts of it is a useful proxy. It's a bit like code coverage: good code coverage is in no way a guarantee that your tests are good, but low coverage is usually a good sign that your tests are not trustworthy. If you can easily come up with good models, it's no guarantee that your operators will, but if you—the author—can't, it's a pretty good sign they'll also have a hard time. Since people in the system are always the last hope of resolving a problem when tooling and automation fails, we should plainly put more effort in supporting them, in providing a good operator experience.