Plato's Dashboards

![[1]](https://commons.wikimedia.org/wiki/File:An_Illustration_of_The_Allegory_of_the_Cave,_from_Plato%E2%80%99s_Republic.jpg){kind=link}
![[2]](https://commons.wikimedia.org/wiki/File:Grafana_dashboard.png){kind=link}
In the allegory, Socrates describes a group of people who have lived chained to the wall of a cave all their lives, facing a blank wall. The people watch graphs projected on the wall from metrics passing in front of a dumpster fire behind them and create dashboards for these metrics. The metrics are the prisoners' reality, but are not accurate representations of the real world.
Socrates explains how the engineer forced to use their own product is like a prisoner who is freed from the cave and comes to understand that the dashboards on the wall are actually not reality at all...
There's going to be nothing new under the sun if I just state that the map is not the territory and that metrics shouldn't end up replacing the thing they aim to measure (cf. Goodhart's Law), and while most people would agree with these ideas in principle, we all tend to behave very differently in practice.
Mostly, the question I ask myself is how do we make sure metrics are properly used to direct attention and orient reactions, rather than taking them for their own reality at the cost of what's both real and important.
So in this post I'm going to go over what makes a good metric, why data aggregation on its own loses resolution and messy details that are often critical to improvements, and that good uses of metrics are visible by their ability to assist changes and adjustments.
What's the Metric For
Earlier this year I was reading Dr. Karen Raymer's thesis, titled "I want to treat the patient, not the alarm": User image mismatch in Anesthesia alarm design, and while I enjoyed the whole read, one of the things that marked me the most was this very first table in the document:
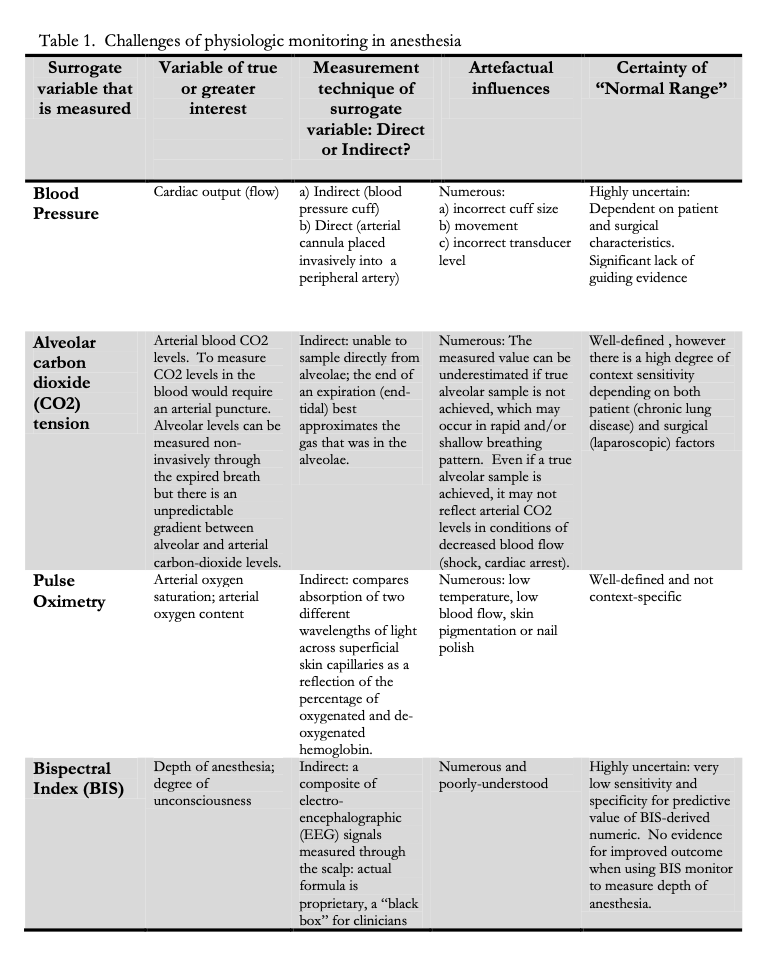
From "I want to treat the patient, not the alarm": User image mismatch in Anesthesia alarm design.
The classification scheme used here is possibly the clearest one I've had the chance to see, one I wish I had seen in use at every place I worked at. Here are the broad categories:
- Surrogate variable that is measured: the thing we measure because it is measurable
- Variable of true or greater interest: the thing we actually want to know about
- Measurement technique of surrogate variable: whether we have the ability to get the actual direct value, or whether it is rather inferred from other observations
- Artefactual influences: what are the things that can mess up the data in measuring it
- Certainty of "Normal Range": how sure are we that the value we read is representative of what we care about?
I don't recall ever seeing an on-call alert have this amount of care in defining what it stands for, including those I defined. And starting to ask these questions quickly creates a very strong contrast with the seriousness we give to some metrics. Do you even have clearly defined variables of true or greater interest?
Particularly in bigger organizations with lots of services where a standard has to be adopted, you often end up in a situation where you track things like "95th percentile of response time is under 100ms for 99% of minutes for each reporting period" or "99.95% of responses return a status code below 500" (meaning "successful or not broken by our fault"). So sure, those are the surrogate variables. What's the true one? User satisfaction? How "snappy" the product feels? Are the metrics chosen truly representative of that experience? What are the things that can pollute or mess with this measurement? Have we even asked these questions, or did we just go with a value some FAANG player published 10 years ago?
Let's pick user satisfaction as a variable of greater interest. What easily measurable proxy variables do we have? User satisfaction surveys? The number of support tickets opened? Reviews on external sites? If any of these are moderately acceptable, how often do they move in conjunction with your latency and error rate? If multiple metrics were adequate surrogates for user satisfaction, you'd expect most of them to react together in cases of disruptions from time to time, otherwise where is the causal link?
And really, to me, that's sort of the core point. Can you describe what the metric stands for in enough detail to know when it's irrelevant and you're free to disregard it, or when it's important stuff you actually need to worry about? Do we have enough clues about the context we're in to know when they're normal and abnormal regardless of pre-defined thresholds? If we don't, then we're giving up agency and just following the metric. We're driving our vehicle by looking at the speed dial, and ignoring the road.
Incidents and useless targets
It's one thing to deal with performance indicators at the service level like response times or status codes. These tend to retain a semantic sense because they measure something discrete, regardless of what they're a surrogate variable for and how much distance they have from the variable of greater interest. The information they carry makes sense to the engineer and can be useful.
Things get funkier when we have to deal with far more vague variables with less obvious causal relationships, and a stronger emotional component attached to them.
MTBF and MTTR are probably the best recent examples there, with good take-downs posted in the VOID Report and Incident Metrics in SRE. One of the interesting aspects of these values is that they especially made sense in the context of mechanical failures for specific components, due to wear and tear, with standard replacement procedures. Outside of that context, they lose all predictive ability because the types of failures and faults are much more varied, for causes often not related to mechanical wear and tear, and for which no standard replacement procedures apply.
It is, in short, a rather bullshit metric. It is popular, a sort of Zombie idea that refuses to die, and one that is easy to measure rather than meaningful.
Incident response and post-incident investigations tend to invite a lot of similar kneejerk reactions. Can we track any sort of progress to make sure we aren't shamed for our incidents in the future? It must be measured! Maybe, but to me it feels like a lot of time is spent collecting boilerplate and easily measurable metrics rather than determining if they are meaningful. The more interesting question is whether the easy metrics are an effective approach to track and find things to improve compared to other ones. Put another way, I don't really care if your medicine is more effective than placebos when there already exists some effective stuff out there.
Deep Dives and Messy Details
So what's more effective? One of my favorite examples comes from the book Still Not Safe: Patient Safety and the Middle-Managing of American Medicine. They look at the performance of anesthesia as a discipline, which has had great successes over the last few decades (anesthesia-mortality risk has declined tenfold since the 1970s), and compare it to the relative lack of success in improving patient safety in the rest of American (and UK) healthcare despite major projects trying to improve things there.
They specifically state:
[A]nesthesia was not distracted into a fruitless and sterile campaign to stamp out “errors,” as would occur in the broader patient safety movement. This is likely due to the substantive influence of nonclinical safety scientists whose field was beginning to develop new thinking about human performance. This new thinking held that “errors” were not causes but rather were consequences; that they did not occur at random but were intimately connected to features of the tools, tasks, and work environment. Thus they were symptoms of deeper problems requiring investigation, not evils to be eliminated by exhortation, accountability, punishment, procedures, and technology.
[...]
Anesthesia’s successful method was largely intensive—detailed, in-depth analysis of single cases chosen for their learning potential (often but not always critical incidents). The broader patient safety field used a health services research approach that was largely extensive—aggregation of large numbers of cases chosen for a common property (an “error” or a bad outcome) and averaging of results across the aggregate. In the extensive approach, the contributory details and compensatory actions that would be fundamentally important to safety scientists tend to disappear, averaged out in the aggregate as “messy details.” [...] The extensive approach is typical of scientific-bureaucratic medicine—the thinking that nothing much can be learned from individual cases (which in medicine are profanely dismissed as mere anecdotes), that insight comes from studying the properties of the aggregate. This approach has its roots in public health and epidemiology, not clinical care; it is exemplified by the movements for clinical practice guidelines and “evidence-based medicine,” with their implicit valuing of the group over the individual good. Thus the two fields used fundamentally different scientific and philosophical approaches, but no one remarked on the differences because the assumptions underpinning them were taken for granted and not articulated.
The importance of this difference is underscored by the early history of safety efforts in anesthesia. The earliest work conducted in the 1950s (e.g., Beecher) used a traditional epidemiological approach, and got nowhere. (Other early efforts outside of anesthesia similarly foundered.) Progress came only after a fundamental and unremarked shift in the investigative approach, one focusing on the specific circumstances surrounding an accident—the “messy details” that the heavy siege guns of the epidemiological approach averaged out or bounded out. These “messy details,” rather than being treated as an irrelevant nuisance, became instead the focus of investigation for Cooper and colleagues and led to progress on safety.
The high-level metrics can tell you about trends and possibly disruptions—such as tracking the number of deaths per procedure. But the actual improvements that were effective were the results of having a better understanding of work itself, by focusing on the messy details of representative cases to generate insights.
This is where practices such as Qualitative research come into play, with approaches like Grounded Theory, which leave room to observation and exploration to produce better hypotheses. This approach may be less familiar to people who, like me, mostly learned about research in elementary and high school science classes and were left with a strawman of the scientific method focused on "picking one hypothesis to explain something and then trying to prove or disprove it". The dynamic between approaches is often discussed in terms of Qualitative vs. Quantitative research, with mixed methods often being used.
I have a gut feeling that software engineers often act like they have some inferiority complex with regards to other engineering disciplines (see Hillel Wayne's Crossover Project for a great take on this) and tend to adopt methods that feel more "grown up"—closer to "hard" sciences—without necessarily being more effective. When it comes to improving safety and the records of whole organization around incidents, the phenomena are highly contextual, and approaches centered on numerical data may prove to be less useful than those aiming to provide understanding even if they aren't as easily measurable in a quantifiable way.
What's the Reaction?
So let's circle back to metrics and ways to ensure we use them for guidance rather than obey them reflexively. Metrics are absolutely necessary to compress complex phenomena into an easily legible value that can guide decision-making. They are, however, lossy compression, meaning that without context, we can't properly interpret the data.
A trick Vanessa Huerta Granda gives is to present the metrics you were asked for, but contextualize them by carrying the story, themes, qualitative details, and a more holistic view of everything that was in place. This is probably the best advice you can find if you really can't get away with changing or dropping the poorer metrics.
But if you're in control? I like to think of this quote from Systemantics:
THE MEANING OF A COMMUNICATION IS THE BEHAVIOUR THAT RESULTS.
The value I get out of a metric is in communicating something that should result in a change or adjustment within the system. For example, Honeycomb customers were asking how long of a time window they should use for their SLOs. Seven days, fourteen days? Should the windows line up with customer events or any specific cycle? My stance simply is: whatever makes them the most effective for you to discuss and act on a burning SLO as a team.
At the very basic level, you get the alarm, you handle the incident, and you’re done. At more advanced levels, the SLO is usable as a prioritization tool for you and your team and your organization to discuss and shape the type of work you want to do. You can treat it as an error budget to be more or less careful, as a reminder to force chaos experiments if you’re not burning it enough—to keep current in your operational practices—or as an early signal for degradations that can take a longer time (weeks/months) to address and scale up.
But all these advanced use cases only come from the SLOs being successfully used to drive and feed discussions. If you feel that one week gives you a perfect way to discuss weekly planning whenever it rolls over, that works. If your group prefers a 2 weeks duration to compare week-over-week and avoid papering this week’s issues because they’re gonna be budgeted next week only, then that works as well. Experiment and see what gets the best adoption or gives your group the most effective reaction you can be looking for, besides the base alerting.
The actual value is not in the metric nor the alert, but in the reaction that follows. They're a great trigger point for more meaningful things to happen, and maintaining that meaningfulness should be the priority.