You Reap What You Code
This is a loose transcript of my talk at Deserted Island DevOps Summer Send-Off, an online conference in COVID-19 times. One really special thing about it is that the whole conference takes place over the Animal Crossing video game, with quite an interesting setup.
It was the last such session of the season, and I was invited to present with few demands. I decided to make a compressed version of a talk I had been mulling over for close to a year, and had lined up for at least one in-person conference that got cancelled/reported in April and had given in its fill hour-long length internally at work. The final result is a condensed 30 minutes that touches all kinds of topics, some of which have been borrowed from previous talks and blog posts of mine.
If I really wanted to, I could probably make one shorter blog post out of every one or two slides in there, but I decided to go for coverage rather than depth. Here goes nothing.

So today I wanted to give a talk on this tendency we have as software developers and engineers to write code and deploy things that end up being a huge pain to live with, to an extent we hadn't planned for.
In software, a pleasant surprise is writing for an hour without compiling once and then it works; a nasty surprise is software that seems to work and after 6 months you find out it poisoned your life.
This presentation is going to be a high level thing, and I want to warn you that I'm going to go through some philosophical concerns at first, follow that up with research that has taken place in human factors and cognitive science, and tie that up with broad advice that I think could be useful to everyone when it comes to system thinking and designing things. A lot of this may feel a bit out there, but I hope that by the end it'll feel useful to you

This is the really philosophical stuff we're starting with. Ivan Illich was a wild ass philosopher who hated things like modern medicine and mandatory education. He wrote this essay called "Energy and Equity" (to which I was introduced by reading a Stephen Krell presentation), where he decides to also dislike all sorts of motorized transportation.
Ivan Illiches introduces the concept of an "oppressive" monopoly; if we look at societies that developed for foot traffic and cycling, you can generally use any means of transportation whatsoever and effectively manage to live and thrive there. Whether you live in a tent or a mansion, you can get around the same.
He pointed out that cycling was innately fair because it does not require more energy than what is required as a baseline to operate: if you can walk, you can cycle, and cycling, for the same energy as walking, is incredibly more efficient. Cars don't have that; they are rather expensive, and require disproportionate amounts of energy compared to what a basic person has.
His suggestion was that all non-freight transport, whether cars or busses and trains, be capped to a fixed percentage above the average speed of a cyclist, which is based on the power a normal human body can produce on its own. He suggested we do this to prevent...

that!
We easily conceived cars as ways to make existing burdens easier: it created freedoms, widened our access to goods and people. It was a better horse, and a less exhausting bicycle. And so society would develop to embrace cars in its infrastructure.
Rather than having a merchant bring goods to the town square, the milkman drop milk on the porch, and markets smaller and distributed closer to where they'd be convenient, it is now everyone's job to drive for each of these things while stores go to where land is cheap rather than where people are. And when society develops with a car in mind, you now need a car to be functional.
In short the cost of participating in society has gone up, and that's what an oppressive monopoly is.

To me, the key thing that Illich did was twist the question another way: what effects would cars have on society if a majority of people had them, and what effect would it have on the rest of us?
The question I now want to ask is whether we have the equivalent in the software world. What are the things we do that we perceive increase our ability to do things, but turn out to actually end up costing us a lot more to just participate?
We kind of see it with our ability to use all the bandwidth a user may have; trying to use old dial-up connections is flat out unworkable these days. But do we have the same with our cognitive cost? The tooling, the documentation, the procedures?

I don't have a clear answer to any of this, but it's a question I ask myself a lot when designing tools and software.
The key point is that the software and practices that we choose to use is not just something we do in a vacuum, but part of an ecosystem; whatever we add to it changes and shifts expectations in ways that are out of our control, and impacts us back again. The software isn't trapped with us, we're trapped with the software.
Are we not ultimately just making our life worse for it? I want to focus on this part where we make our own life, as developers, worse. When we write or adopt software to help ourselves but end up harming ourselves in the process, because that speaks to our own sustainability.

Now we're entering the cognitive science and human factors bit.
Rather than just being philosophical here I want to ground things in the real world with practical effects. Because this is something that researchers have covered. The Ironies of automation are part of cognitive research (Bainbridge, 1983) that looked into people automating tasks and finding out that the effects weren't as good as expected.
Mainly, it's attention and practice clashing. There are tons of examples over the years, but let's take a look at a modern one with self-driving cars.
Self-driving cars are a fantastic case of clumsy automation. What most established players in the car industry are doing is lane tracking, blind spot detection, and handling parallel parking.
But high tech companies (Tesla, Waymo, Uber) are working towards full self-driving, with Tesla's autopilot being the most ambitious one being released to the public at large. But all of these right now operate in ways Bainbridge fully predicted in 1983:
- the driver is no longer actively involved and is shifted to the role of monitoring
- the driver, despite no longer driving the car, regardless must be fully aware of everything the car is doing
- when the car gets in a weird situation, it is expected that the driver takes control again
- so the car handles all the easy cases, but all the hard cases are left to the driver
Part of the risk there is twofold: people have limited attention for tasks they are not involved in—if you're not actively driving it's going to be hard to be attentive for extended periods of time—and if you're only driving rarely with only the worst cases, you risk being out of practice to handle the worst cases.
Such automation is done in airlines who otherwise make up for it in simulator hours, and still manually handling planned difficult areas like takeoff and landing. Still, a bunch of airline incidents discover that this hand-off is often complex and not going well.
Clearly, when we ignore the human component and its responsibilities in things, we might make software worse than what it would have been.

In general most of these errors come from the following point of view. This is called the "Fitts" model, also "HABA-MABA", for "Humans are better at, machines are better at" (the original version was referred as MABA-MABA, using "Men" rather than "Humans"). This model frames humans as slow, perceptive beings able of judgement, and machines are fast undiscerning indefatigable things.
We hear this a whole lot even today. These things are, to be polite, a beginner's approach to automation design. It's based on scientifically outdated concepts, intuitive-but-wrong sentiments, and is comforting in letting you think that only the predicted results will happen and totally ignores any emergent behaviour. It operates on what we think we see now, not on stronger underlying principles, and often has strong limitations when it comes to being applied in practice.
It is disconnected from the reality of human-machine interactions, and frames choices as binary when they aren't, usually with the intent of pushing the human out of the equation when you shouldn't. This is, in short, a significant factor behind the ironies of automation.

Here's a patched version established by cognitive experts. They instead reframe the human-computer relationship as a "joint cognitive system", meaning that instead of thinking of humans and machines as unrelated things that must be used in distinct contexts for specific tasks, we should frame humans and computers as teammates working together. This, in a nutshell, shifts the discourse from how one is limited to terms of how one can complement the other.
Teammates do things like being predictable to each other, sharing a context and language, being able to notice when their actions may impact others and adjust accordingly, communicate to establish common ground, and have an idea of everyone's personal and shared objectives to be able to help or prioritize properly.
Of course we must acknowledge that we're nowhere close to computers being teammates as the state of the art today. And since currently computers need us to keep realigning them all the time, we have to admit that the system is not just the code and the computers, it's the code, the computers, and all the people who interact with them and each other. And if we want our software to help us, we need to be able to help it, and to help it that means the software needs to be built knowing it will be full of limitations and having us work to make it easier to diagnose issues and form and improve mental models.
So the question is: what makes a good model? How can we help people work with what we create?
note: this slide and the next one are taken from my talk on operable software
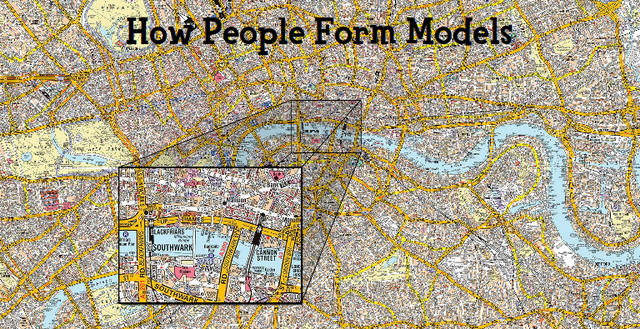
This is a map of the city of London, UK. It is not the city of London, just a representation of it. It's very accurate: it has streets with their names, traffic directions, building names, rivers, train stations, metro stations, footbridges, piers, parks, gives details regarding scale, distance, and so on. But it is not the city of London itself: it does not show traffic nor roadwork, it does not show people living there, and it won't tell you where the good restaurants are. It is a limited model, and probably an outdated one.
But even if it's really limited, it is very detailed. Detailed enough that pretty much anyone out there can't fit it all in their head. Most people will have some detailed knowledge of some parts of it, like the zoomed-in square in the image, but pretty much nobody will just know the whole of it in all dimensions.
In short, pretty much everyone in your system only works from partial, incomplete, and often inaccurate and outdated data, which itself is only an abstract representation of what goes on in the system. In fact, what we work with might be more similar to this:
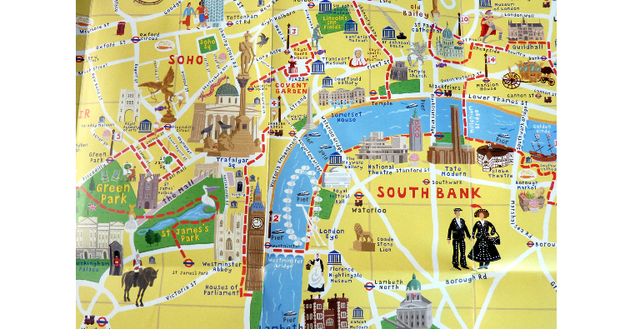
That's more like it. This is still not the city of London, but this tourist map of London is closer to what we work with. Take a look at your architecture diagrams (if you have them), and chances are they look more like this map than the very detailed map of London. This map has most stuff a tourist would want to look at: important buildings, main arteries to get there, and some path that suggests how to navigate them. The map has no well-defined scale, and I'm pretty sure that the two giant people on Borough road won't fit inside Big Ben. There are also lots of undefined areas, but you will probably supplement them with other sources.
But that's alright, because mental models are as good as their predictive power; if they let you make a decision or accomplish a task correctly, they're useful. And our minds are kind of clever in that they only build models as complex as they need to be. If I'm a tourist looking for my way between main attractions, this map is probably far more useful than the other one.
There's a fun saying about this: "Something does not exist until it is broken." Subjectively, you can be entirely content operating a system for a long time without ever knowing about entire aspects of it. It's when they start breaking or that your predictions about the system no longer works that you have to go back and re-tune your mental models. And since this is all very subjective, everyone has different models.
This is a vague answer to what is a good model, and the follow up is how can we create and maintain them?

One simple step, outside of all technical components, is to challenge and help each other to sync and build better mental models. We can't easily transfer our own models to each other, and in fact it's pretty much impossible to control them. What we can do is challenge them to make sure they haven't eroded too much, and try things to make sure they're still accurate, because things change with time.
So in a corporation, things we might do include training, documentation, incident investigations all help surface aspects and changes to our systems to everyone. Game days and chaos engineering are also excellent ways to discover how our models might be broken in a controlled setting.
They're definitely things we should do and care about, particularly at an organisational level. That being said, I want to focus a bit more on the technical stuff we can do as individuals.
note: this slide is explored more in depth in my talk on operable software
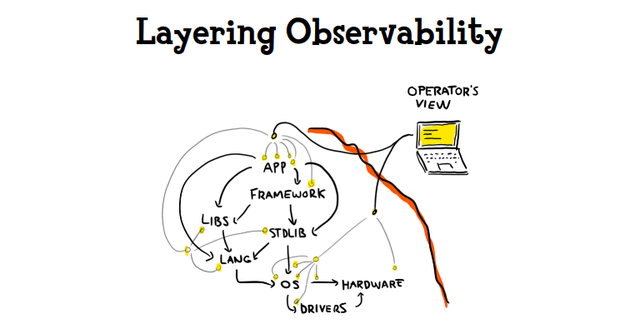
We can't just open a so-called glass pane and see everything at once. That's too much noise, too much information, too little structure. Seeing everything is only useful to the person who knows what to filter in and filter out. You can't easily form a mental model of everything at once. To aid model formation, we should structure observability to tell a story.
Most applications and components you use that are easy to operate do not expose their internals to you, they mainly aim to provide visibility into your interactions with them. There has to be a connection between the things that the users are doing and the impact it has in or on the system, and you will want to establish that. This means:
- Provide visibility into interactions between components, not their internals
- log at the layer below which you want to debug, which saves time and how many observability probes you need to insert in your code base. We have a tendency to stick everything at the app level, but that's misguided.
- This means the logs around a given endpoint have to be about the user interactions with that endpoint, and require no knowledge of its implementation details
- For developer logs, you can have one log statement shared by all the controllers by inserting it a layer below endpoints within the framework, rather than having to insert one for each endpoint.
- These interactions will let people make a mental picture of what should be going on and spot where expectations are broken more easily. By layering views, you then make it possible to skip between layers according to which expectations are broken and how much knowledge they have
- Where a layer provides no easy observability, people must cope through inferences in the layers above and below it. It becomes a sort of obstacle.
Often we are stuck with only observability at the highest level (the app) or the lowest level (the operating system), with nearly nothing useful in-between. We have a blackbox sandwich where we can only look at some parts, and that can be a consequence of the tools we choose. You'll want to actually pick runtimes and languages and frameworks and infra that let you tell that observability story and properly layer it.

Another thing to help with model formation is maintaining that relationship between humans and machines going smoothly. This is a trust relationship, and providing information that is considered misleading or unhelpful erodes that trust. There are a few things you can do with logs that can help not ruin your marriage to the computer.
The main one is to log facts, not interpretations. You often do not have all the context from within a single log line, just a tiny part of it. If you start trying to be helpful and suggesting things to people, you change what is a fact-gathering expedition into a murder-mystery investigations where bits of the system can't be trusted or you have to rean between the lines. That's not helpful. A log line that says TLS validation error: SEC_ERROR_UNKNOWN_ISSUER is much better than one that says ERROR: you are being hacked regardless of how much experience you have.
A thing that helps with that is structured logging, which is better than regular text. It makes it easier for people to use scripts or programs to parse, aggregate, route, and transform logs. It prevents you from needing full-text search to figure out what happened. If you really want to provide human readable text or interpretations, add it to a field within structured logging.
Finally, adopting consistent naming mechanisms and units is always going to prove useful.

There is another thing called the Law of Requisite Variety, which says that only complexity can control complexity. If an agent can't represent all the possible states and circumstances around a thing it tries to control, it won't be able to control it all. Think of an airplane's flight stabilizers; they're able to cope only with a limited amount of adjustment, and usually at a higher rate than we humans could. Unfortunately, once it reaches a certain limit in its actions and things it can perceive, it stops working well.
That's when control is either ineffective, or passed on to the next best things. In the case of software we run and operate, that's us, we're the next best thing. And here we fall into the old idea that if you are as clever as you can to write something, you're in trouble because you need to be doubly as clever to debug it.
That's because to debug a system that is misbehaving under automation, you need to understand the system, and then understand the automation, then understand what the automation thinks of the system, and then take action.
That's always kind of problematic, but essentially, brittle automation forces you to know more than if you had no automation in order to make things work in difficult times. Things can then become worse than if you had no automation in the first place.

When you start creating a solution, do it while being aware that it is possibly going to be brittle and will require handing control over to a human being. Focus on the path where the automation fails and how the hand-off will take place. How are you going to communicate that, and which clues or actions will an operator have to take over things?
When we accept and assume that automation will reach its limits, and the thing that it does is ask a human for help, we shift our approach to automation. Make that hand-off path work easily. Make it friendly, and make it possible for the human to understand what the state of automation was at a given point in time so you can figure out what it was doing and how to work around it. Make it possible to guide the automation into doing the right thing.
Once you've found your way around that, you can then progressively automate things, grow the solution, and stay in line with these requirements. It's a backstop for bad experiences, similar to "let it crash" for your code, so doing it well is key.

Another thing that I think is interesting is the curb cut effect. The curb cut effect was noticed as a result from the various American laws about accessibility that started in the 60s. The idea is that to make sidewalks and streets accessible to people in wheelchairs, you would cut the part of the curb so that it would create a ramp from sidewalk to street.
The thing that people noticed is that even though you'd cut the curb for handicapped people, getting around was now easier for people carrying luggage, pushing strollers, on skateboards or bicycles, and so on. Some studies saw that people without handicaps would even deviate from their course to use the curb cuts.
Similar effects are found when you think of something like subtitles which were put in place for people with hearing problems. When you look at the raw number of users today, there are probably more students using them to learn a second or third language than people using them with actual hearing disabilities. Automatic doors that open when you step in front of them are also very useful for people carrying loads of any kind, and are a common example of doing accessibility without "dumbing things down."
I'm mentioning all of this because I think that keeping accessibility in mind when building things is one of the ways we can turn nasty negative surprises into pleasant emerging behaviour. And generally, accessibility is easier to build in than to retrofit. In the case of the web, accessibility also lines up with better performance.
If you think about diversity in broader terms, how would you rethink your dashboards and monitoring and on-call experience if you were to run it 100% on a smartphone? What would that let people on regular computers do that they cannot today? Ask the same question but with user bases that have drastically different levels of expertise.
I worked with an engineer who used to work in a power station and the thing they had set up was that during the night, when they were running a short shift, they'd generate an audio file that contained all the monitoring metrics. They turned it into a sort of song, and engineers coming in in the morning would listen to it on fast forward to look for anomalies.
Looking at these things can be useful. If you prepare for your users of dashboards to be colorblind, would customizing colors be useful? And could that open up new regular use cases to annotate metrics that tend to look weird and for which you want to keep an eye on?
And so software shouldn't be about doing more with less. It's actually requiring less to do more. As in letting other people do more with less.

note: this slide is a short version of my post on Complexity Has to Live Somewhere
A thing we try to do, especially as software engineers, is to try to keep the code and the system—the technical part of the system—as simple as possible. We tend to do that by finding underlying concepts, creating abstractions, and moving things outside of the code. Often that means we rely on some sort of convention.
When that happens, what really goes on is that the complexity of how you chose to solve a problem still lingers around. Someone has to handle the thing. If you don't, your users have to do it. And if it's not in the code, it's in your operators or the people understanding the code. Because if the code is to remain simple, the difficult concepts you abstracted away still need to be understood and present in the world that surrounds the code.
I find it important to keep that in mind. There's this kind of fixed amount of complexity that moves around the organization, both in code and in the knowledge your people have.
Think of how people interact with the features day to day. What do they do, how does it impact them? What about the network of people around them? How do they react to that? Would you approach software differently if you think that it's still going to be around in 5, 10, or 20 years when you and everyone who wrote it has left? If so, would that approach help people who join in just a few months?
One of the things I like to think about is that instead of using military analogies of fights and battles, it's interesting to frame it in terms of gardens or agriculture. When we frame the discussion that we have in terms of an ecosystem and the people working collectively within it, the way we approach solving problems can also change drastically.

Finally, one of the things I want to mention briefly is this little thought framework I like when we're adopting new technology.
One we first adopt a new piece of technology, the thing we try to do—or tend to do—is to start with the easy systems first. Then we say "oh that's great! That's going to replace everything we have." Eventually, we try to migrate everything, but it doesn't always work.
So an approach that makes sense is to start with the easy stuff to probe that it's workable for the basic cases. But also try something really, really hard, because that would be the endpoint. The endgame is to migrate the hardest thing that you've got.
If you're not able to replace everything, consider framing things as adding it to your system rather than replacing. It's something you add to your stack. This framing is going to change the approach you have in terms of teaching, maintenance, and in terms of pretty much everything that you have to care about so you avoid the common trap of deprecating a piece of critical technology with nothing to replace it. If you can replace a piece of technology then do it, but if you can't, don't fool yourself. Assume the cost of keeping things going.
The third one there is diffusing. I think diffusing is something we do implicitly when we do DevOps. We took the Ops responsibilities and the Dev responsibilities and instead of having it in different areas and small experts in dev and operation, you end up making it everybody's responsibility to be aware of all aspects.
That creates that diffusion where in this case, it can be positive. You want everyone to be handling a task. But if you look at the way some organisations are handling containerization, it can be a bunch of operations people who no longer have to care about that aspect of their job. Then all of the development teams now have to know and understand how containers work, how to deploy them, and just adapt their workflow accordingly.
In such a case we haven't necessarily replaced or removed any of the needs for deployment. We've just taken it outside of the bottleneck and diffused it and sent it to everyone else.
I think having an easy way, early in the process, to figure out whether what we're doing is replacing, adding, or diffusing things will drastically influence how we approach change at an organisational level. I think it can be helpful.

This is all I have for today. Hopefully it was practical.
Thanks!