A Commentary on Defining Observability
Recently, Hazel Weakly has published a great article titled Redefining Observability. In it, she covers competing classical definitions observability, weaknesses they have, and offers a practical reframing of the concept in the context of software organizations (well, not only software organizations, but the examples tilt that way).
I agree with her post in most ways, and so this blog post of mine is more of an improv-like “yes, and…” response to it, in which I also try to frame the many existing models as complementary or contrasting perspectives of a general concept.
The main points I’ll try to bring here are on the topics of the difference between insights and questions, the difference between observability and data availability, reinforcing a socio-technical definition, the mess of complex systems and mapping them, and finally, a hot take on the use of models when reasoning about systems.
Insights and Questions
The control theory definition of observability, from Rudolf E. Kálmán, goes as follows:
Observability is a measure of how well internal states of a system can be inferred from knowledge of its external outputs.
The one from Woods and Hollnagel in cognitive engineering goes like this:
Observability is feedback that provides insight into a process and refers to the work needed to extract meaning from available data.
Hazel version’s, by comparison, is:
Observability is the process through which one develops the ability to ask meaningful questions, get useful answers, and act effectively on what you learn.
While all three definitions relate to extracting information from a system, Hazel’s definition sits at a higher level by specifically mentioning questions and actions. It’s a more complete feedback loop including some people, their mental models, and seeking to enrich them or use them.
I think that higher level ends up erasing a property of observability in the other definitions: it doesn’t have to be inquisitive nor analytical.
Let’s take a washing machine, for example. You can know whether it is being filled or spinning by sound. The lack of sound itself can be a signal about whether it is running or not. If it is overloaded, it might shake a lot and sound out of balance during the spin cycle. You don’t necessarily have to be in the same room as the washing machine nor paying attention to it to know things about its state, passively create an understanding of normalcy, and learn about some anomalies in there.
Another example here would be something as simple as a book. If you’re reading a good old paper book, you know you’re nearing the end of it just by how the pages you have read make a thicker portion of the book than those you haven’t read yet. You do not have to think about it, the information is inherent to the medium. An ebook read on an electronic device, however, will hide that information unless a design decision is made to show how many lines or words have been read, display a percentage, or a time estimate of the content left.
Observability for the ebook isn’t innate to its structure and must be built in deliberately. Similarly, you could know old PCs were doing heavy work if the disk was making noise and when the fan was spinning up; it is not possible to know as much on a phone or laptop that has an SSD and no fan unless someone builds a way to expose this data.
Associations and patterns can be formed by the observer in a way that provides information and explanations, leading to effective action and management of the system in play. It isn’t something always designed or done on purpose, but it may need to be.
The key element is that an insight can be obtained without asking questions. In fact, a lot of anomaly detection is done passively, by the observer having a sort of mental construct of what normal is that lets them figure out what should happen next—what the future trajectory of the system is—and to then start asking questions when these expectations are not met. The insights, therefore, can come before the question is asked. Observability can be described as a mechanism behind this.
I don’t think that this means Hazel’s definition is wrong; I think it might just be a consequence of the scale at which her definition operates. However, this distinction is useful for a segue into the difference between data availability and observability.
The difference between observability and data availability
For a visual example, I’ll use variations on a painting from 1866 named In a Roman Osteria, by Danish painter Carl Bloch:

The first one is an outline, and the second is a jigsaw puzzle version (with all the pieces are right side up with the correct orientation, at least).
The jigsaw puzzle has 100% data availability. All of the information is there and you can fully reconstruct the initial painting. The outlined version has a lot less data available, but if you’ve never seen the painting before, you will get a better understanding from it in absolutely no time compared to the jigsaw.
This “make the jigsaw show you what you need faster” approach is more or less where a lot of observability vendors operate: the data is out there, you need help to store it and put it together and extract the relevancy out of it:

What this example highlights though is that while you may get better answers with richer and more accurate data (given enough time, tools, and skill), the outline is simpler and may provide adequate information with less effort required from the observer. Effective selection of data, presented better, may be more appropriate during high-tempo, tense situations where quick decisions can make a difference.
This, at least, implies that observability is not purely a data problem nor a tool problem (which lines up, again, with what Hazel said in her post). However, it hints at it being a potential design problem. The way data is presented, the way affordances are added, and whether the system is structured in a way that makes storytelling possible all can have a deep impact in how observable it turns out to be.
Sometimes, coworkers mention that some of our services are really hard to interpret even when using Honeycomb (which we build and operate!) My theory about that is that too often, the data we output for observability is structured with the assumption that the person looking at it will have the code on hand—as the author did when writing it—and will be able to map telemetry data to specific areas of code.
So when you’re in there writing queries and you don’t know much about the service, the traces mean little. As a coping mechanism, social patterns emerge where data that is generally useful is kept on some specific spans that are considered important, but that you can only find if someone more familiar with this area explained where it was to you already. It draws into pre-existing knowledge of the architecture, of communication patterns, of goals of the application that do not live within the instrumentation.
Traces that are easier to understand and explore make use of patterns that are meaningful to the investigator, regardless of their understanding of the code. For the more “understandable” telemetry data, the naming, structure, and level of detail are more related to how the information is to be presented than the structure of the underlying implementation.
Observability requires interpretation, and interpretation sits in the observer. What is useful or not will be really hard to predict, and people may find patterns and affordances in places that weren’t expected or designed, but still significant. Catering to this property requires taking a perspective of the system that is socio-technical.
The System is Socio-Technical
Once again for this section, I agree with Hazel on the importance of people in the process. She has lots of examples of good questions that exemplify this. I just want to push even harder here.
Most of the examples I’ve given so far were technical: machines and objects whose interpretation is done by humans. Real complex systems don’t limit themselves to technical components being looked at; people are involved, talking to each other, making decisions, and steering the overall system around.
This is nicely represented by the STELLA Report’s Above/Below the line diagram:
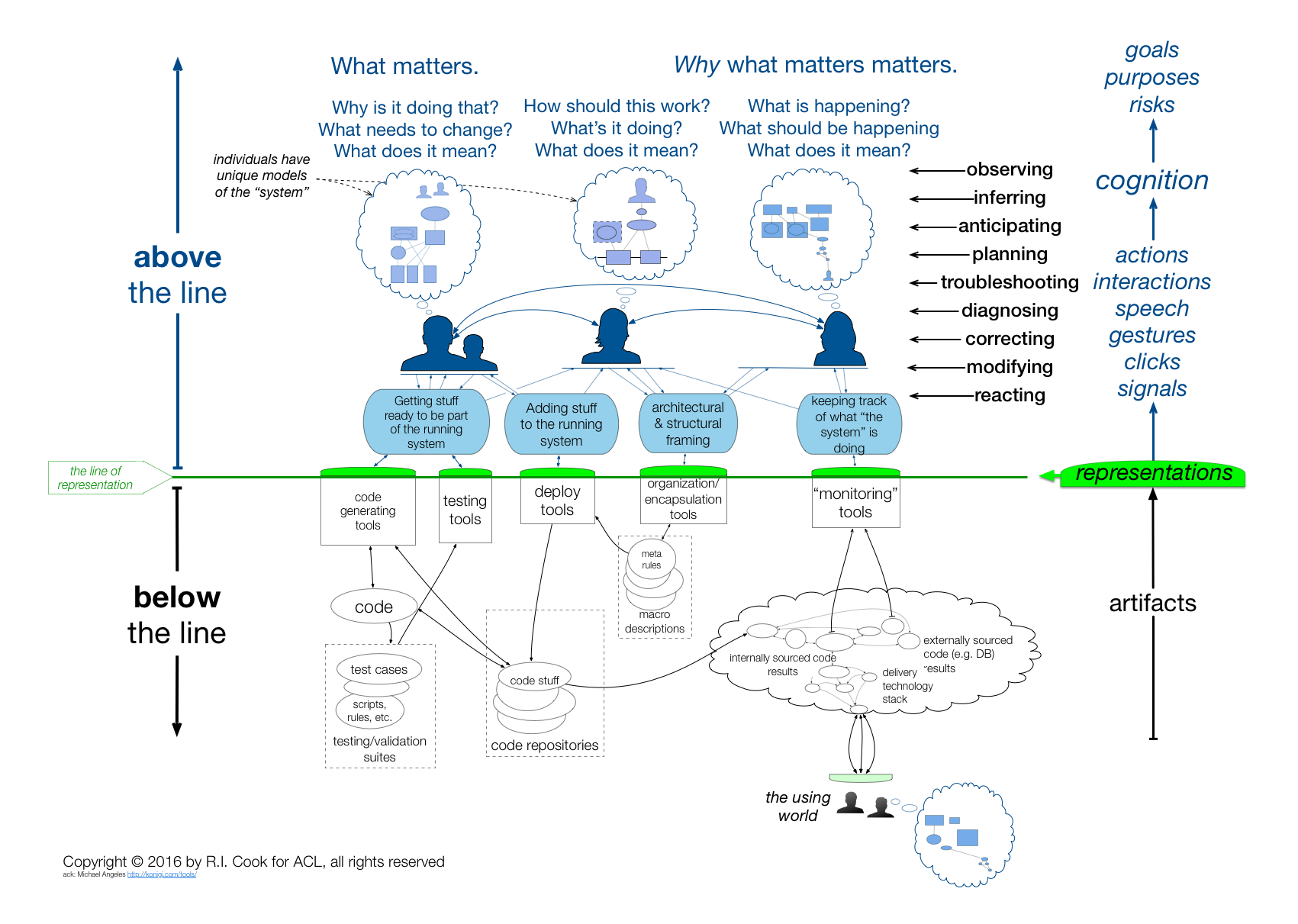
The continued success of the overall system does not purely depend on the robustness of technical components and their ability to withstand challenges for which they were designed. When challenges beyond what was planned for do happen, and when the context in which the system operates changes (whether it is due to competition, legal frameworks, pandemics, or evolving user needs and tastes), adjustments need to be made to adapt the system and keep it working.
The adaptation is not done purely on a technical level, by fixing and changing the software and hardware, but also by reconfiguring the organization, by people learning new things, by getting new or different people in the room, by reframing the situation, and by steering things in a new direction. There is a constant gap to bridge between a solution and its context, and the ability to anticipate these challenges, prepare for them, and react to them can be informed by observability.
Observability at the technical level (“instrument the code and look at it with tools”) is covered by all definitions of observability in play here, but I want to really point out that observability can go further.
If you reframe your system as properly socio-technical, then yes you will need technical observability interpreted at the social level. But you may also need social observability handled at the social level: are employees burning out? Do we have the psychological safety required to learn from events? Do I have silos of knowledge that render my organization brittle? What are people working on? Where is the market at right now? Are our users leaving us for competition? Are our employees leaving us for competitions? How do we deal with a fast-moving space with limited resources?
There are so many ways for an organization to fail that aren’t technical, and ideally we’d also keep an eye on them. A definition of observability that is technical in nature can set artificial boundaries to your efforts to gain insights from ongoing processes. I believe Hazel’s definition maps to this ideal more clearly than the cognitive engineering one, but I want to re-state the need to avoid strictly framing its application to technical components observed by people.
A specific dynamic I haven’t mentioned here—and this is something disciplines like cybernetics, cognitive engineering, and resilience engineering all have interests for—is one where the technical elements of the system know about the social elements of the system. We essentially do not currently have automation (nor AI) sophisticated enough to be good team members.
For example, while I can detect a coworker is busy managing a major outage or meeting with important customers in the midst of a contract renewal, pretty much no alerting system will be able to find that information and decide to ask for assistance from someone else who isn’t as busy working on high-priority stuff within the system. The ability of one agent to shape their own work based on broader objectives than their private ones is something that requires being able to observe other agents in the system, map that to higher goals, and shape their own behaviour accordingly.
Ultimately, a lot of decisions are made through attempts at steering the system or part of it in a given direction. This needs some sort of [mental] map of the relationships in the system, and an even harder thing to map out is the impact of having this information will have on the system itself.
Complex Systems Mapping Themselves
Recently I was at work trying to map concepts about reliability, and came up with this mess of a diagram showing just a tiny portion of what I think goes into influencing system reliability (the details are unimportant):
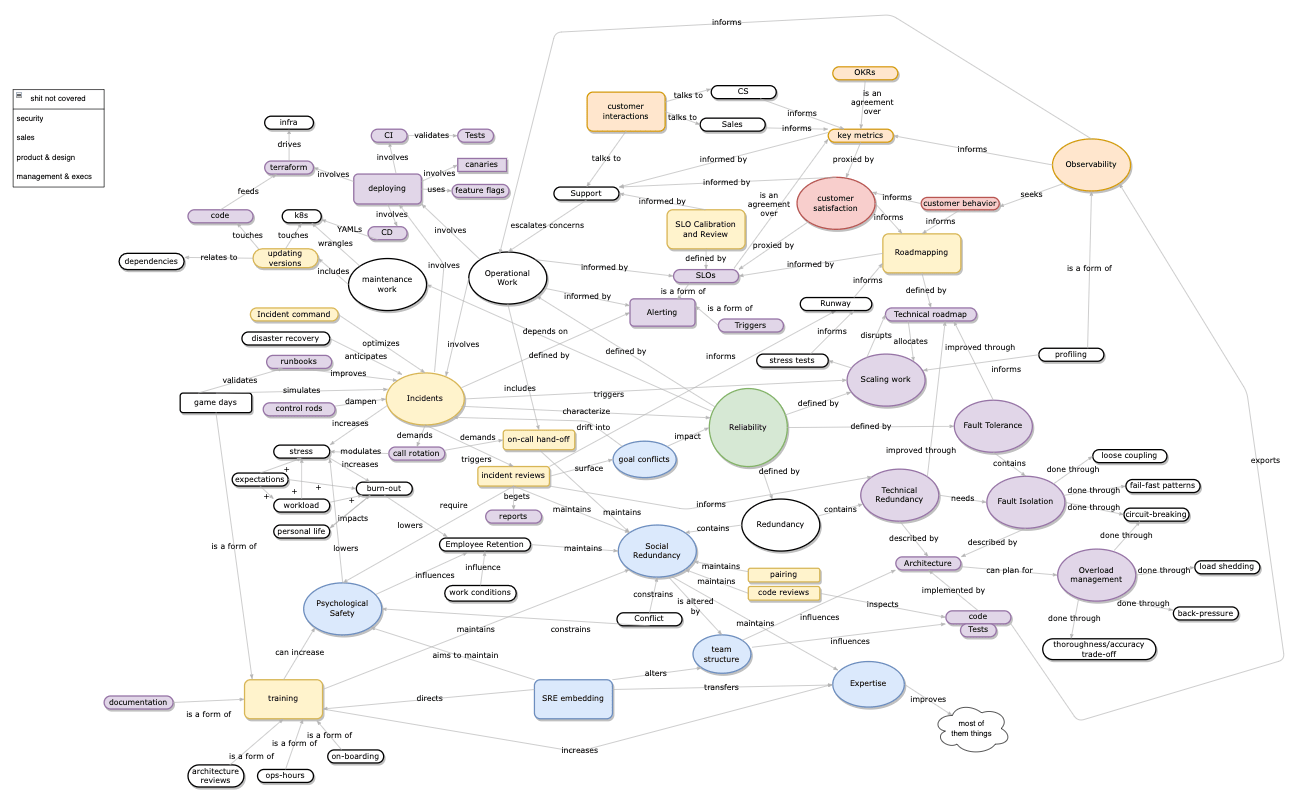
In this concept map, very few things are purely technical; lots of work is social, process-driven, and is about providing feedback loops. As the system grows more complex, analysis and control lose some power, and sense-making and influence become more applicable.
The overall system becomes unknowable, and nearly impossible to map out—by the time the map is complete, it’s already outdated. On top of that, the moment the above map becomes used to make decisions, its own influence might need to become part of itself, since it has entered the feedback loop of how decisions are made. These things can’t be planned out, and sometimes can only be discovered in a timely manner by acting.
Basically, the point here is that not everything is observable via data availability and search. Some questions you have can only be answered by changing the system, either through adding new data, or by extracting the data through probing of the system. Try a bunch of things and look at the consequences.
A few years ago, I was talking with David Woods (to be exact, he was telling me useful things and I was listening) and he compared complex socio-technical systems to a messy web; everything is somehow connected to everything, and it’s nearly impossible to just keep track of all the relevant connections in your head. Things change and some elements will be more relevant today than they were yesterday. As we walk the web, we rediscover connections that are important, some that stopped being so significant, and so on.
Experimental practices like chaos engineering or fault injection aren’t just about testing behaviour for success and failure, they are also about deliberately exploring the connections and parts of the web we don’t venture into as often as we’d need to in order to maintain a solid understanding of it.
One thing to keep in mind is that the choice of which experiment to run is also based on the existing map and understanding of situations and failures that might happen. There is a risk in the planners and decision-makers not considering themselves to be part of the system they are studying, and of ignoring their own impact and influence.
This leads to elements such as pressures, goal conflicts, and adaptations to them, which may tend to only become visible during incidents. The framing of what to investigate, how to investigate it, how errors are constructed, which questions are worth asking or not worth asking all participate to the weird complex feedback loop within the big messy systems we’re in. The tools required for that level of analysis are however very, very different from what most observability vendors provide, and are generally never marketed as such, which does tie back on Hazel’s conclusion that “observability is organizational learning.”
A Hot Take on the Use of Models
Our complex socio-technical systems aren’t closed systems. Competitors exist; employees bring in their personal life into their work life; the environment and climate in which we live plays a role. It’s all intractable, but simplified models help make bits of it all manageable, at least partially. A key criterion is knowing when a model is worth using and when it is insufficient.
Hazel Weakly again hints at this when she states:
- The control theory version gives you a way to know whether a system is observable or not, but it ignores the people and gives you no way to get there
- The cognitive engineering version is better, but doesn’t give you a “why” you should care, nor any idea of where you are and where to go
- Her version provides a motivation and a sense of direction as a process
I don’t think these versions are in conflict. They are models, and models have limits and contextual uses. In general I’d like to reframe these models as:
- What data may be critical to provide from a technical component’s point of view (control theory model)
- How people may process the data and find significance in it (cognitive engineering model)
- How organizations should harness the mechanism as a feedback loop to learn and improve (Hazel Weakly’s model)
They work on different concerns by picking a different area of focus, and therefore highlight different parts of the overall system. It’s a bit like how looking at phenomena at a human scale with your own eyes, at a micro scale with a microscope, and at an astronomical scale with a telescope, all provide you with useful information despite operating at different levels. While the astronomical scale tools may not bear tons of relevance at the microscopic scale operations, they can all be part of the same overall search of understanding.
Much like observability can be improved despite having less data if it is structured properly, a few simpler models can let you make better decisions in the proper context.
My hope here was not to invalidate anything Hazel posted, but to keep the validity and specificity of the other models through additional contextualization.