Negotiable Abstractions
When I used to write more software and do more architecture professionally (I still do, but less intensively so with the SRE title), one of the most important questions I'd seek answers to was "how do I cut this up?" Or more accurately, "how do I cut this up without it coming back to haunt me later?" My favorite guideline was to write code that is easy to delete, not code that is easy to maintain; Tef wrote about this more eloquently than I ever did. I long ago gave up on the idea of writing maintainable code rather than code that was articulated in the right places to make things easy to get rid of.
It's the kind of thing that made sense to me and with which I found more success, but without necessarily having a good underlying principle for it. As I've been slowly writing code for fun in my toy project doing file synchronization, I had the benefit of going slow, thinking longer, and revisiting decisions with rest and no production pressure. A recent change in there, along with tons of reading in the last few years sort of crystallized what feels like a good explanation of it.
In this post I'll cover what theoretically (and often practically) good abstractions require. I'll then use the changes I brought to my toy project to show how factors entirely unrelated to code can drive change and define abstractions, and how these changes in turn can end up re-defining the context in which the code runs, which in turn prompts re-framing the software itself. This, ultimately makes me believe abstractions are contextual, subjective, and therefore negotiable.
Theoretically good abstractions
One of my favorite sources for newer engineers trying to understand how to structure their software is John Ousterhout's A Philosophy of Software Design—I used it to start multiple book clubs in multiple organizations—which I wish had existed when I was newer to this industry.
There are quite a few heuristics in there to judge what makes a good abstraction:
- Modular design is an ideal, which is hard to attain because modules must know about each other, and dependencies force them to change together; modular design minimizes dependencies.
- Dividing interfaces and implementations is how we cut this up, splitting up what and how concerns.
- Abstractions fundamentally omit unimportant details, which let us reason about things more simply. This word, unimportant, will be critical for us here. Abstractions that include unimportant details are more complicated than necessary. Omitting important details will cause confusion.
- As a heuristic, the best abstractions tend to be deep: they have a narrow interface that lets you access a lot of functionality. Shallow modules, which have a wide interface and limited functionality tend to be poor abstractions. File I/O as offered by Linux is mentioned as a good, deep interface.
- A good amount of care is taken to define information hiding and leaking; information leaks when multiple modules are impacted by a design decision.
- It is more important for a module to have a simple interface than a simple implementation
The book contains many examples and tips on what makes abstractions good or bad, and how to recognize problematic ones. These rules of thumbs are all solid and hard to disagree with—many of them put into words things I had been doing for a while when I first read it years ago.
Whether it's tacit or not, these ideas of carefully choosing where complexity should live influence how I approach laying out systems, modules, and code.
Context Drives Change
There are important things that do not show up in code, however, and can come from elements far outside of it. To demonstrate that, I want to describe a recent change I made in ReVault, my toy project that does file synchronization.
To give you some context, ReVault works by scanning directories, getting the hash of files, tracking changes with interval tree clocks, and then comparing manifests to peers to know what needs to be synchronized and whether any concurrent changes happened that should be considered a conflict. Pretty much everything it does deals with files. And so while it was a bit tricky to choose how to cut up the various scanning, networking, and synchronization modules around both code and state boundaries, it was rather straightforward for file handling.
I leaned heavily on the POSIX interface offered by your usual standard library, with functions wrapping higher-level concepts like "serializing data and then overwriting a file safely," while mostly sticking to direct file usage otherwise. The file abstractions were tried and true, and they lined up nicely with all the basic operations I had to deal with. If I had to frame it according to A Philosophy of Software Design's principles, I avoided creating a lot of shallow modules and thin wrappers that provided little in terms of hiding complexity.
Earlier this year, I decided to experiment with an S3-based back-end, which would let me make an off-site copy of some files in a private bucket without needing to secure a VPS or server to make it safe to store data there. I expected this to be a rather straightforward mapping of calls from one interface to another. Sure, S3 is block storage, not file storage, but the API to it is very file-like so most of it ought to be compatible.
And it was, for the most part. The biggest difference for ReVault was that AWS charges per operation. If I left the API the same and just did a one-to-one substitution, all the scans and hash checks on a single synchronization of a moderately small directory could cost me 10 cents each time. This felt like a losing proposition; small frequent changes give the best expected result to reduce the probability of file conflicts, and incentivizing the opposite behavior by charging for empty syncs is ineffective design.
The obvious workarounds including tweaking the software's state machine to scan less if nothing changed, and to cache the hashes when using S3 to avoid re-fetching them if the files haven't changed since last run. Because of how S3 handles listing files, last modified timestamps, and hashes, the cache-based approach could be 20 times cheaper than the naive one.
This cache however only could be reliable and only made sense for S3, not the file system back-end. It also required refactoring the interface to the storage layer: it had to be shifted higher up into the application logic, in order to properly hide caching concerns, compatibility with disk storage, and ways it would intertwine with the state machine.
None of the business rules changed, none of the old file operations or concepts changed. To refer back to Ousterhout's book, nothing important or unimportant changed in what we expose in the interface. What changed is a cost structure, which is connected to contextual priorities (I don't want to pay much for my synchronization) in a way that the code has absolutely no concept of before or after the change.
This is an interesting property to highlight here: what makes a good or bad abstraction may have nothing to do with what is objectively observable in code (which doesn't mean it never does, far from it), and a lot to do with the desires of people around the system.
Change Creates New Contexts
It does not end there though. Somehow, making that well-encapsulated change with a brand new interface messed with other parts of the system as well. And not just in small ways: when I synchronized larger directories, the software would eventually freeze. There was no error, but it would start using so much memory that even the REPL I used to interact with the s3-side local node would freeze entirely and I'd need to hard kill the process: no way to debug it interactively.
What is it about the new file layer that was buggy? As it turns out, nothing. A bit of analysis showed that the S3 layer was perfectly functional, and so was the old disk layer. The new abstraction was fine.
The problem was that because I no longer needed a disk for one of my two peers, I started running both of them on the same computer: one using the disk, and one using S3. That shifted bottlenecks around:
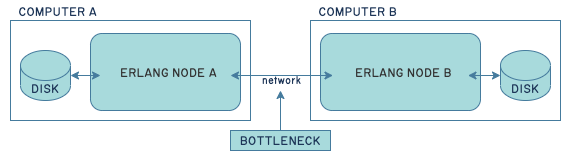
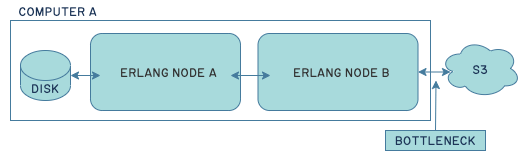
This bottleneck was problematic because there existed one little point of asynchronous communications in the whole pipeline:
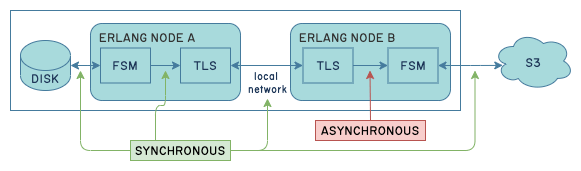
This meant that reading from disk, going over the local network, and pushing data to the remote state machine went unhindered while memory kept accumulating in front of the slower S3 upload until the node became unresponsive. Making that hop between B's TLS and FSM processes synchronous fixed things.
Putting it all together, a change in interface to keep costs low on an otherwise equivalent feature set has an unexpected interaction with how I deploy software that shifts bottlenecks such that I need to adjust network-related communications in an entirely distinct component. Not so self-contained anymore. Even more than that, this whole "bottleneck-centric analysis" was not necessary (even if I was familiar with the concepts and had thought about it a bit) until I started accidentally moving it around and it suddenly gained importance.
Basically, in a world where you have imperfect knowledge that improves over time, the order in which you stumble upon discoveries shapes the system you build, which in turn is impacted in potentially surprising ways by seemingly unrelated changes.
New Contexts Mean New Boundaries
The key point I would make here is that what is important or not—one of the key factors in defining proper abstractions—is not an objective fact encoded into the world. It is a consequence of how we pick and choose boundaries based on anticipated use cases and a limited understanding of the current world, and that is allowed to change.
We like to think of our systems as inherently possible to analyze: we take the current implementation, stakeholders, their needs, and their experience, and if we study it long enough, we will have the ability to generate insights out of it and then create a better, more adequate system. The challenge here is that the rate of change in the world and for our experiences is out of our control. It is impossible for us to know what we will discover only later. Insights are often quite unpredictable. Yet, all of these can have a fundamental impact on how we judge the adequacy of abstractions and established structures.
Even though it is absolutely involved with code, things are important beyond the code, and therefore the abstractions within the code are bound to change due to factors entirely external and unavoidable to it.
But even then, there's something more general here. Every time we define a category, that we decide to re-arrange a messy complex world into neat boxes, we pick a subjective point of reference that defines the ideal case for that label. If I declare the colors "red" and "yellow", there's a gradient where something may be redder and something else yellowish, but there's also a kind of mess around the cases that would fall into the yet-undefined "orange". Whether we need it or not, and what it means to all other color definitions may practically depend on how much we encounter these cases, and how important they are.
Legacy software systems are defined in dozens of ways. My favorite one is probably just "a system that we no longer know how to or have the will to maintain." Another one here might be: a system whose fundamental abstractions are deeply rooted in a context that has changed so much it lost relevance. This may funnily line up with the theory that software engineers have to ditch older systems to truncate their history for code to keep acting as a commodity.
The heuristics given by Ousterhout are still good. I'd like to think they best fit this analytic pattern, the one of a frozen snapshot you reason about. These bouts of analysis must share room and be intertwined with sensemaking, and that can flip things upside down.
If our abstractions are subjective and contextual, then we ought to consider them negotiable. We can decide what makes a better or a worse abstraction based on what we deem important today, even if it's not in the code at all. But like all negotiations, we don't necessarily get to control when or how they happen.
Thanks to Amos King and Clark Lindsay for reviewing this text.